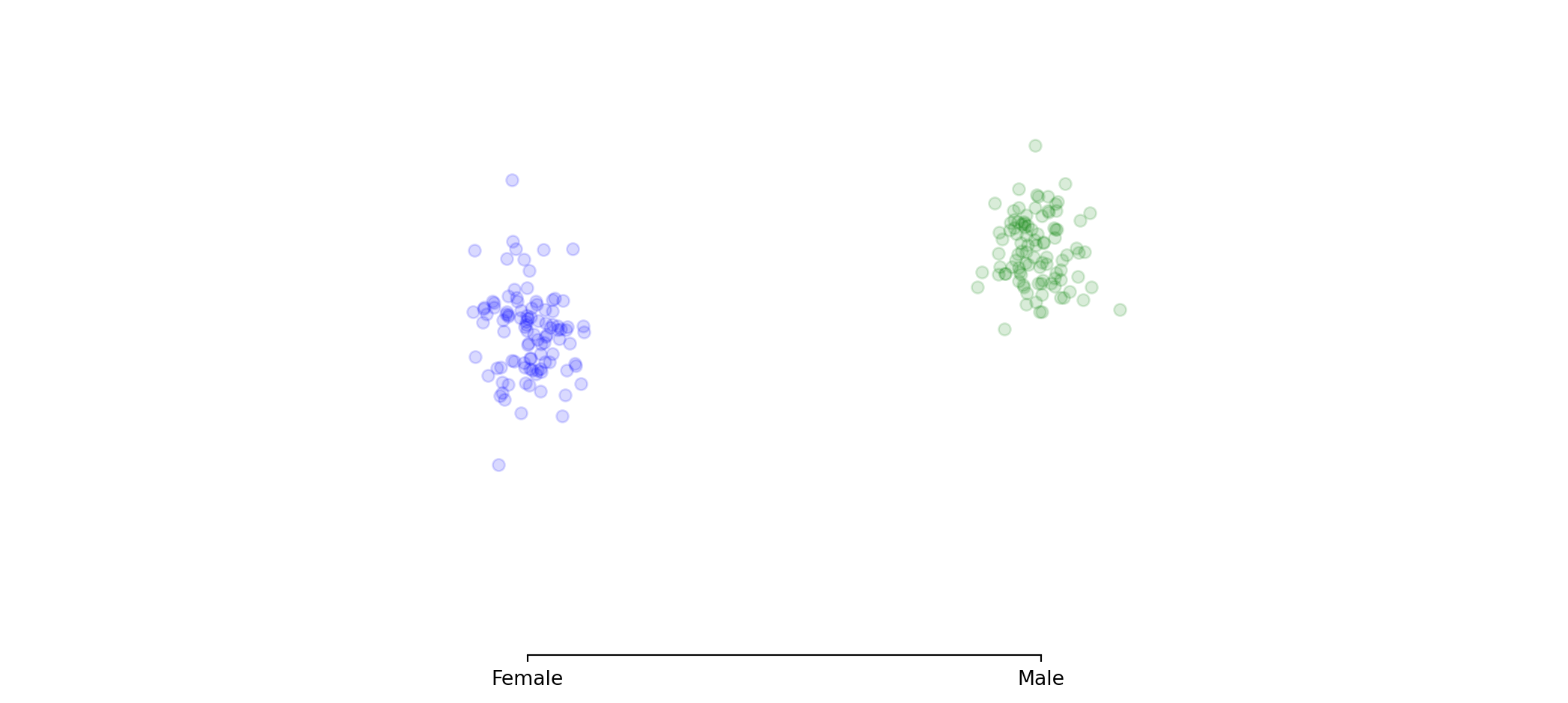
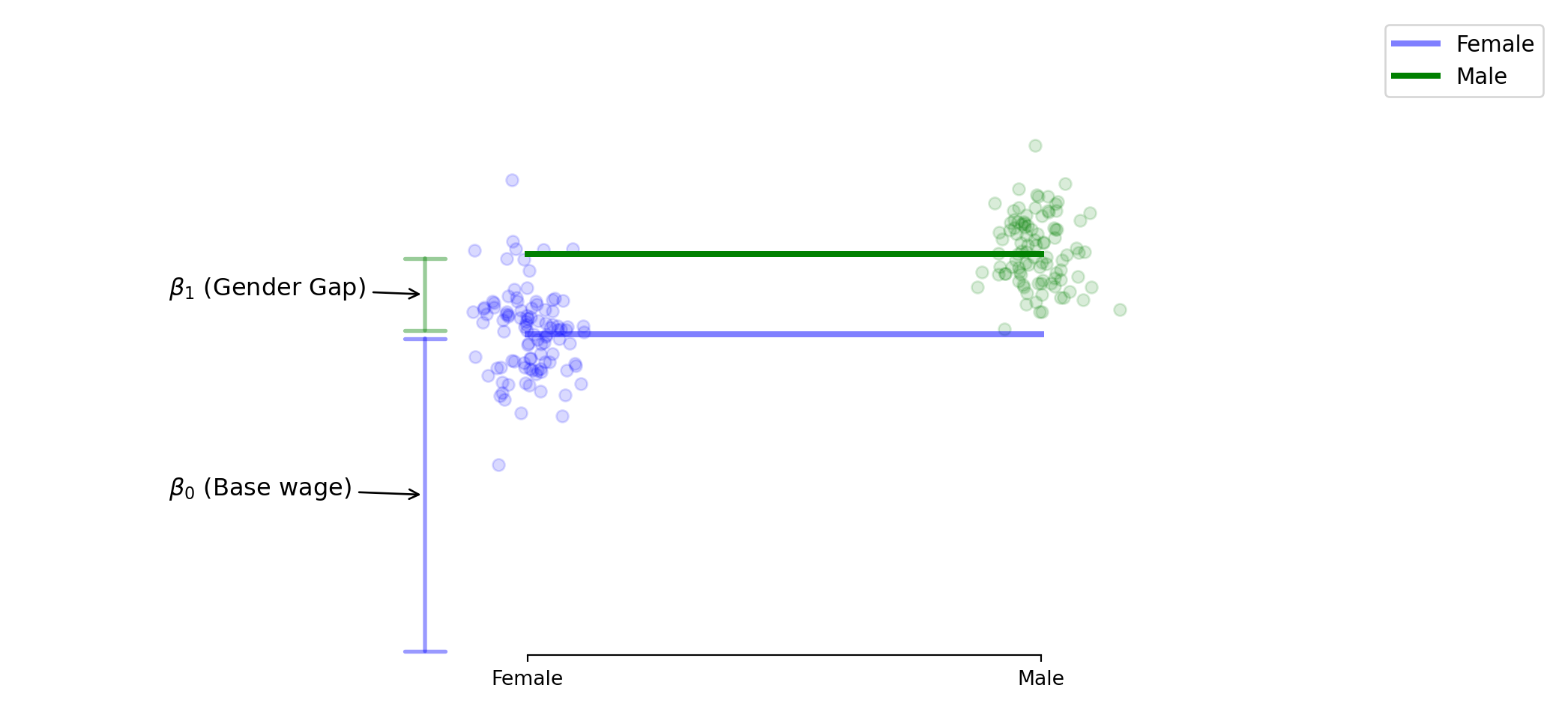
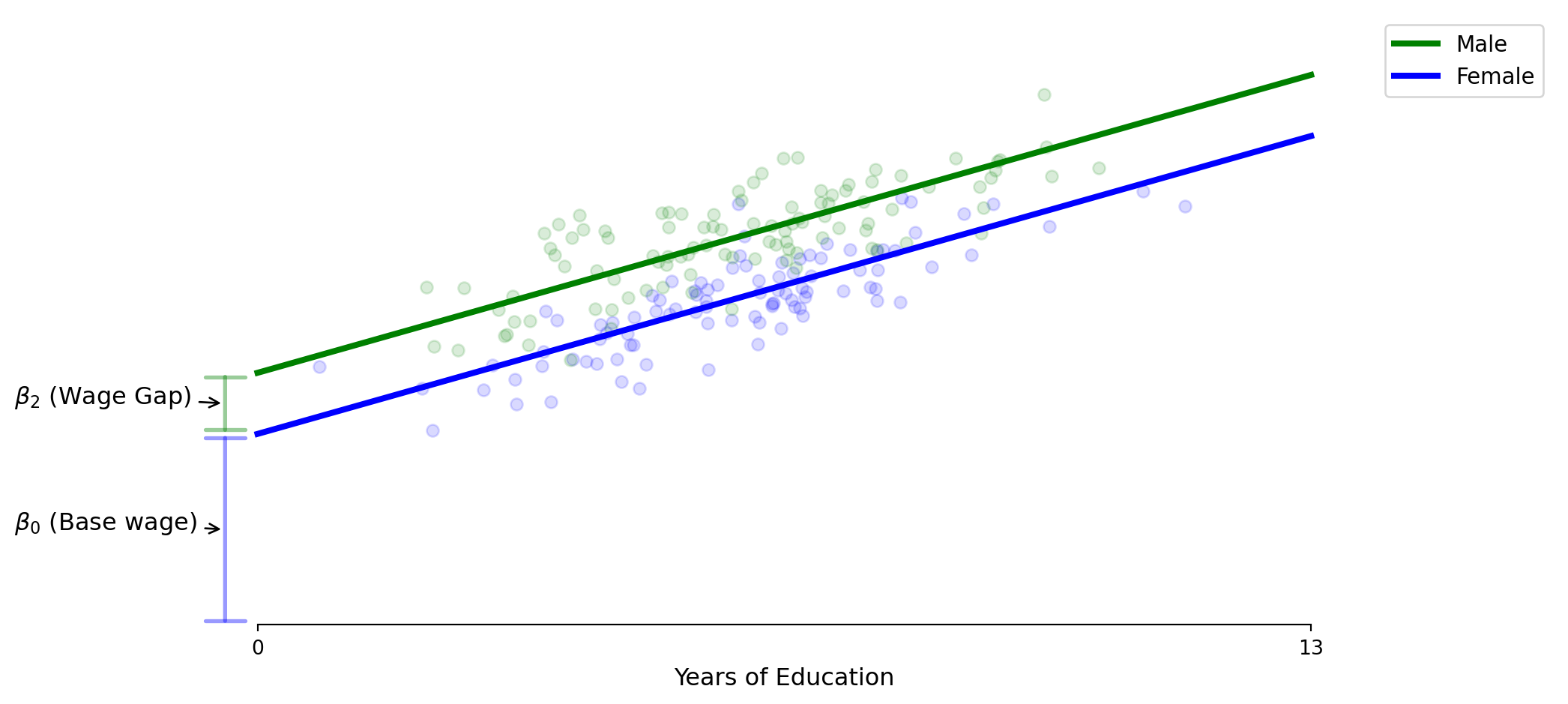
β₁ represents the gender wage gap, the additional wage for male
We often call a Categorical Control variable like this a “Fixed Effect”
Model 1: The Code
Implementing the basic gender gap model
import statsmodels.formula.api as smf# Fit the model with just the male indicatormodel1 = smf.ols('INCLOG10 ~ MALE', data=data).fit()print(model1.summary().tables[1])
If β₁ > 0, this is evidence of a difference in income by gender
There are many possible explainations for this gap
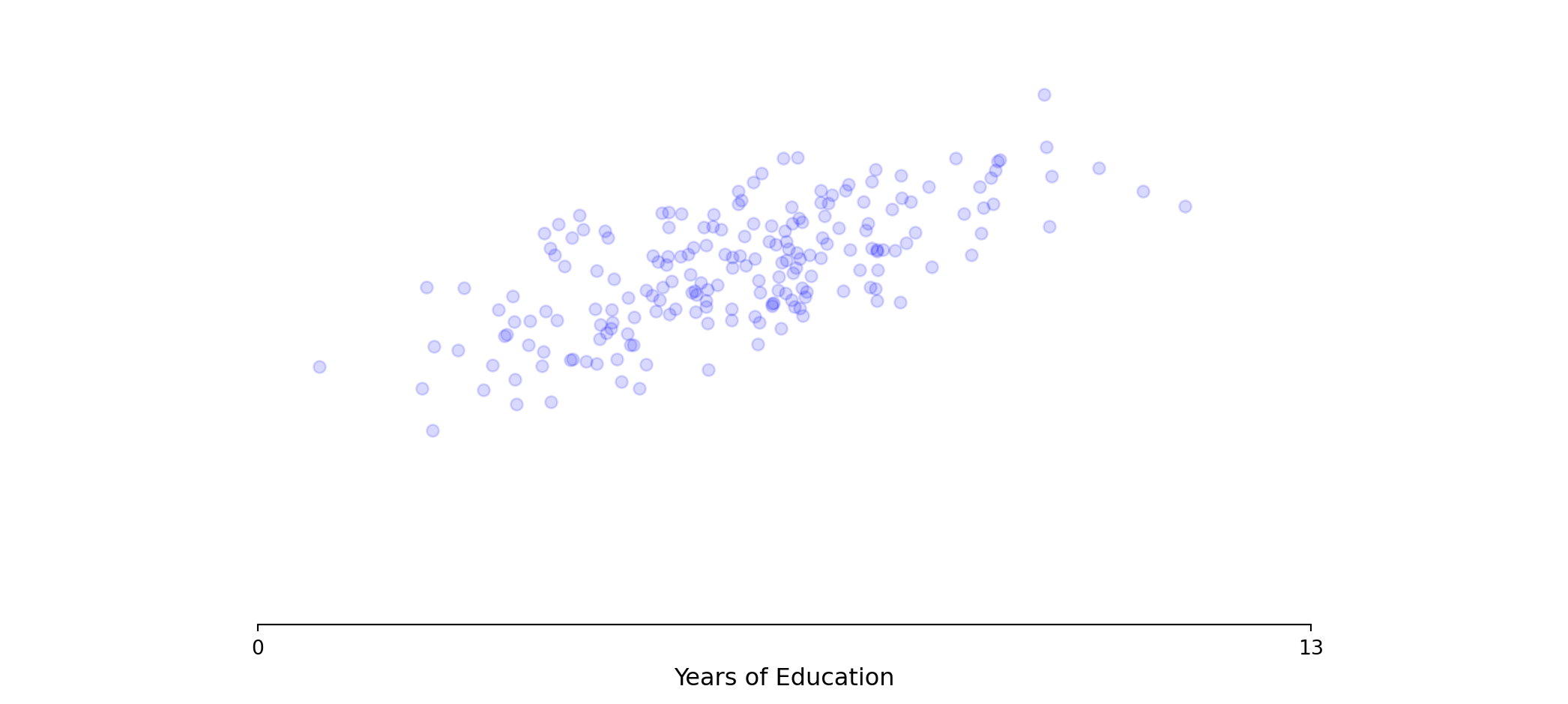
What if the gap is related to some other factor (eg. education)?
> β₀ is the base wage for those with no post-middle school education
> β₂ represents the gender wage gap, added to the intercept for male only
> model assumes parallel lines, same returns to education (β₁) for everyone
Model 2: The Code
Implementing the gender fixed effect model
import statsmodels.formula.api as smf# Fit the model with male indicatormodel2 = smf.ols('INCLOG10 ~ EDU + MALE', data=data).fit()print(model2.summary().tables[1])
If β₂ > 0, there is evidence of a gender wage gap.
Summary: Categorical Controls
What we learned in Part 5.1
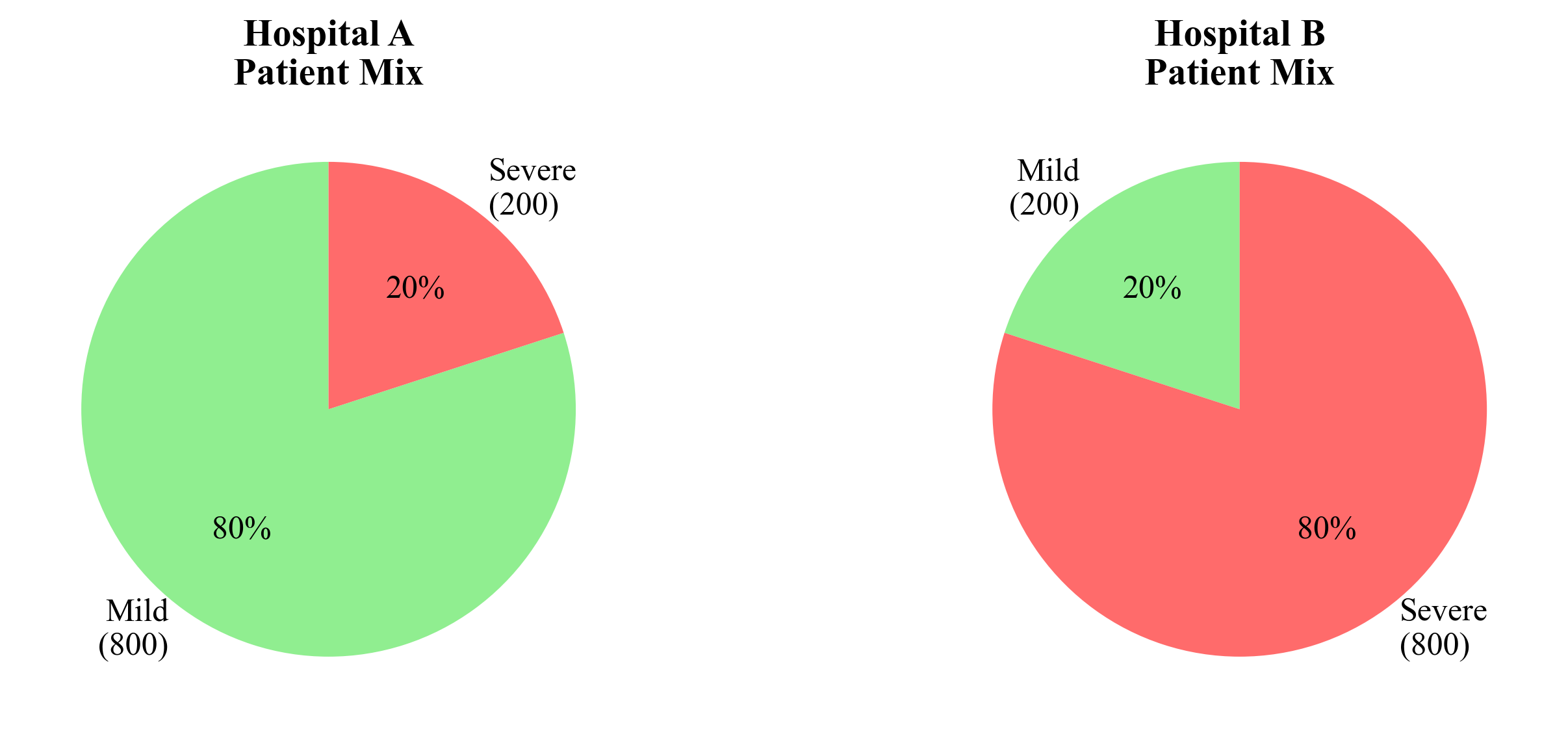
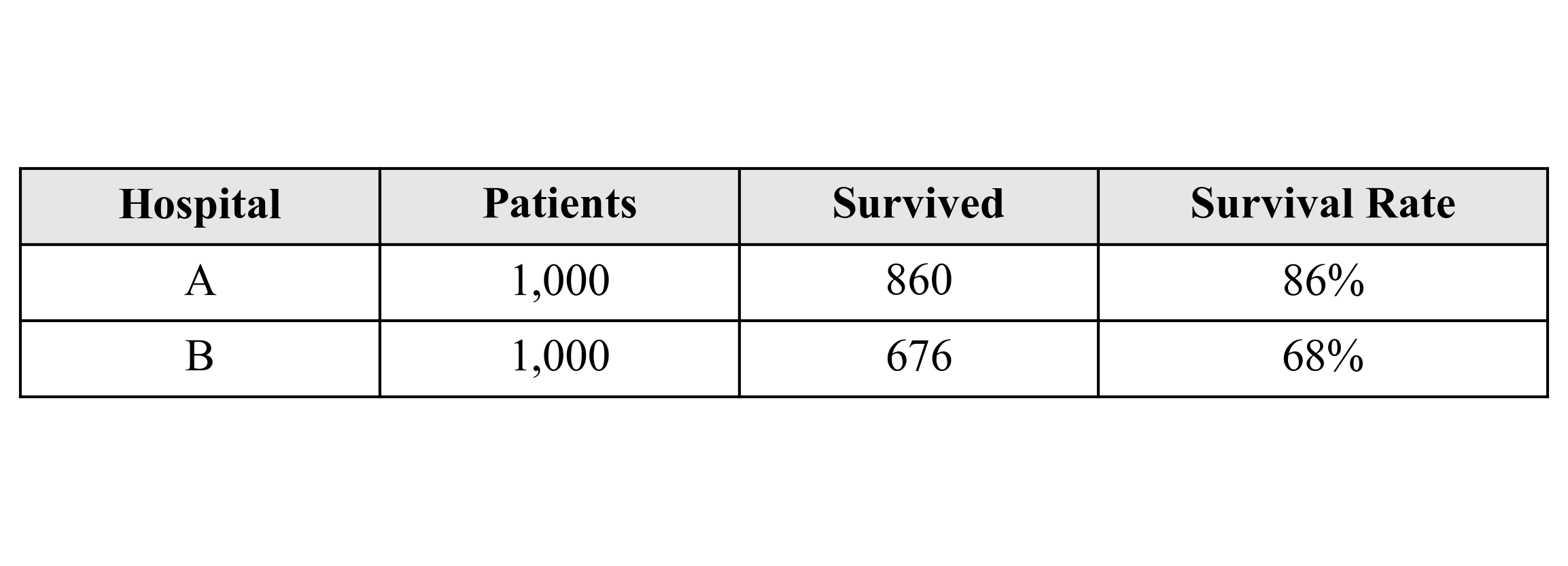
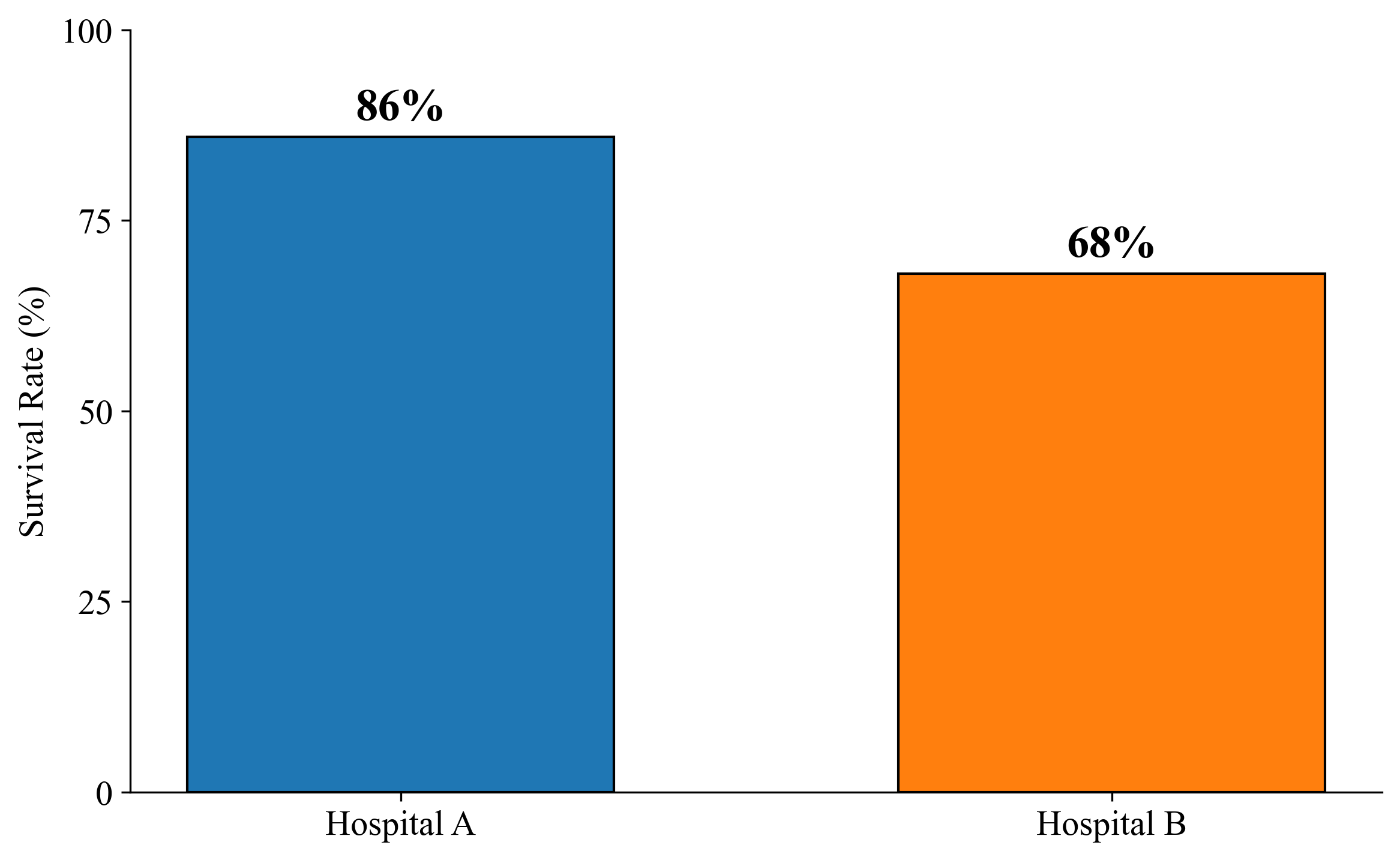
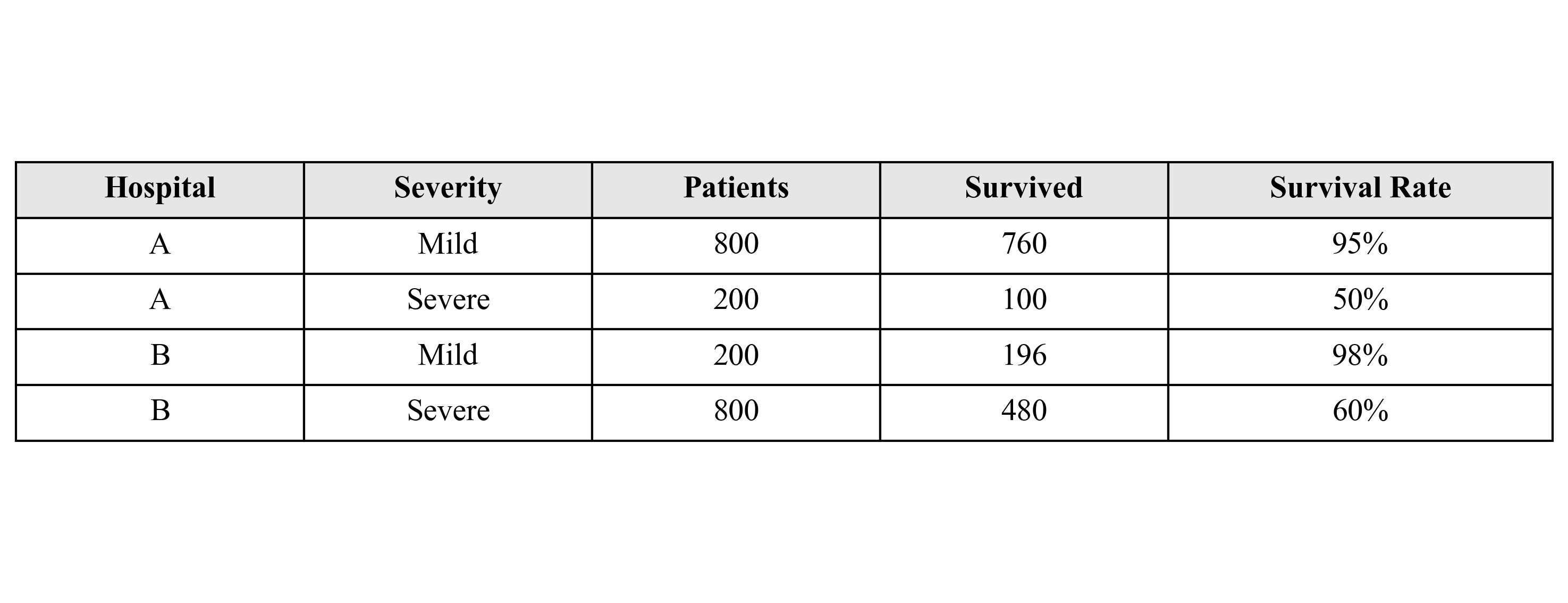
Simpson’s Paradox shows why we need to control for confounding variables
Categorical controls (fixed effects) capture level differences between groups
Model 1: Just the indicator: tests for differences
Model 2: Indicator + continuous variable: parallel lines with different intercepts
Next: What if the slopes differ between groups?: Part 5.2 Interactions