GLM Assumptions
Which model do you think offers better predictions?

GLM Assumptions
Which model do you think offers better predictions?

Model 1 has predictions close to the average data for all predictor values.
Model 2 will offer inaccurate predictions for large predictor variables!
Model Fit
We use residuals (\(\varepsilon\)) and estimates (\(\hat{y}\)) to check if a model is ‘specified’.

Residuals (\(\varepsilon\)): the error of each prediction; how far off the model is.
Estimates (\(\hat{y}\)): the model’s predicted value for each observation.
Assumption 1: Linearity
The error term should be unrelated to the fitted value.
Q. Which model appears to violate the Linearity Assumption?
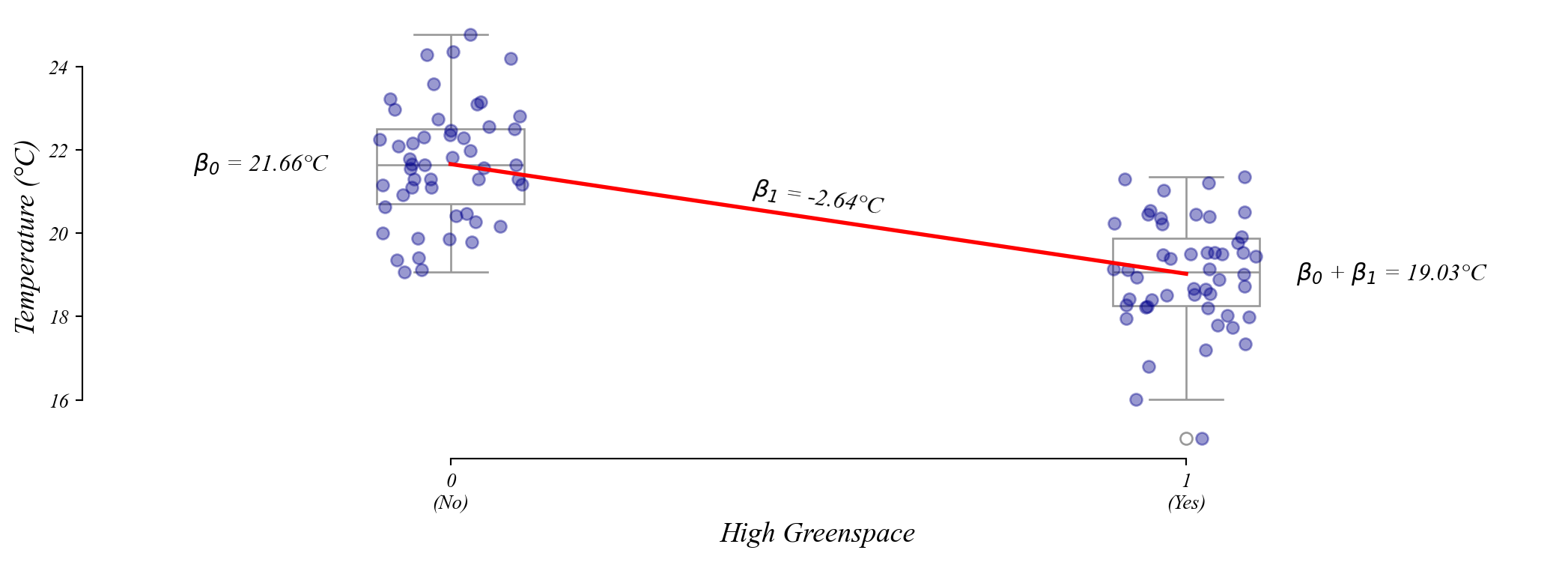
Assumption 1: Linearity
The error term should be unrelated to the fitted value.
Q. Which model appears to violate the Linearity Assumption?

Model 1 is equally wrong everywhere. Model 2 has larger errors at the extremes.
Assumption 1: Linearity
A non-linear relationship will produce non-linear residuals.
The linear model misses the true curvature leading to systematic errors.
Assumption 2: Homoskedasticity
Residuals should be spread out the same everywhere.
Q. Which one of these figures shows homoskedasticity?
Assumption 2: Homoskedasticity
Residuals should be spread out the same everywhere.
Q. Which one of these figures shows homoskedasticity?
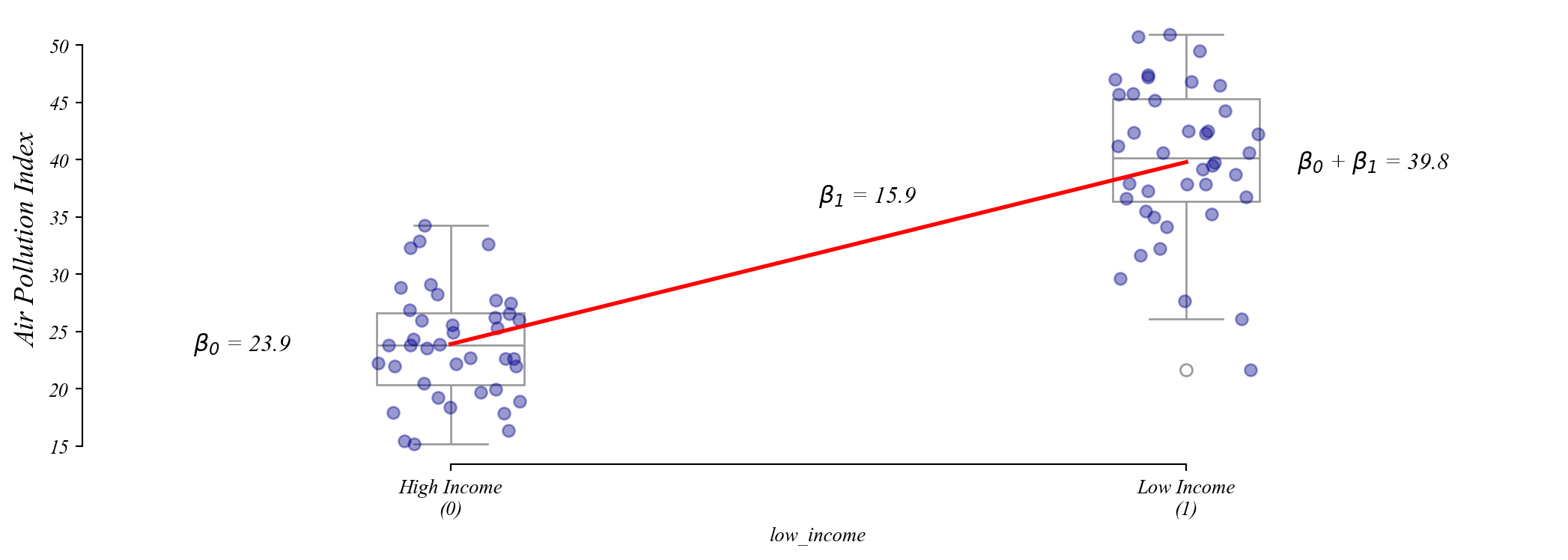
Model 1 is equally wrong everywhere. Model 2 has errors that grow with the fitted value.
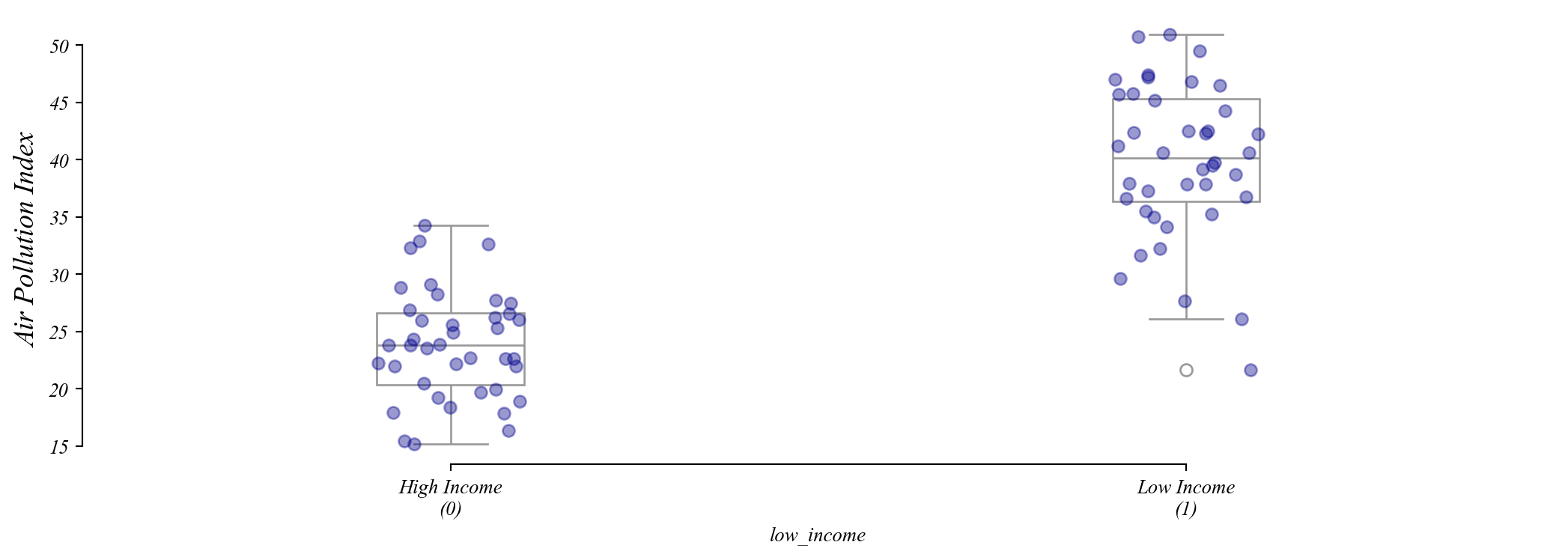
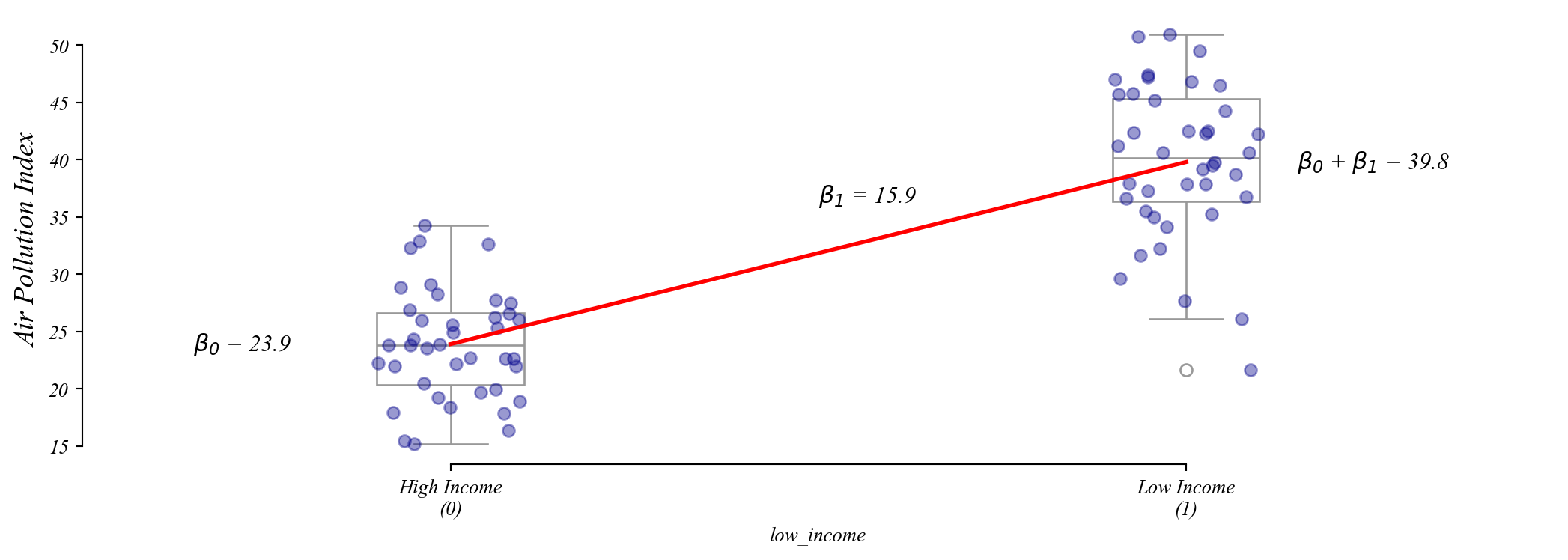
Assumption 2: Homoskedasticity
The spread of residuals should not change across values of X.
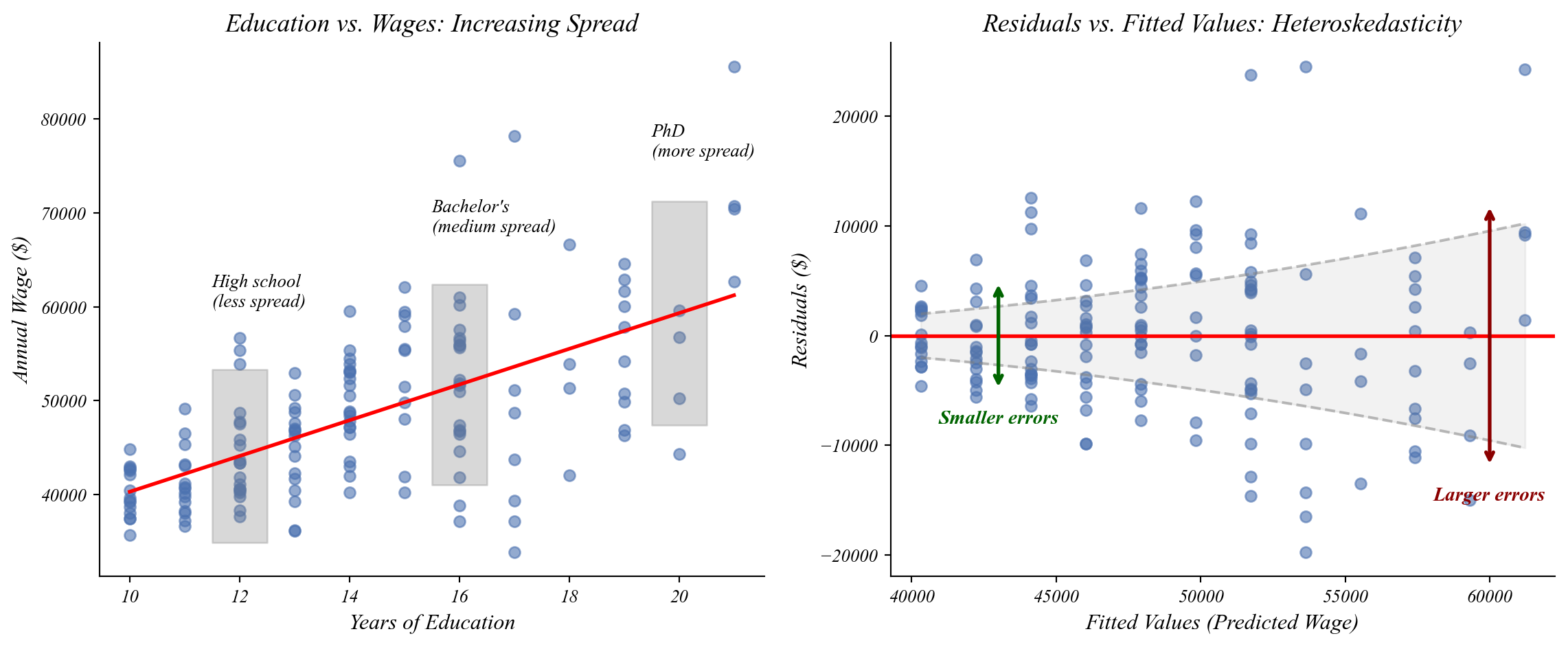
The spread of points increases as education increases!
Assumption 3: Independence
Each error should be unrelated to previous errors.
Q. Which of these residual lag plots shows independence?
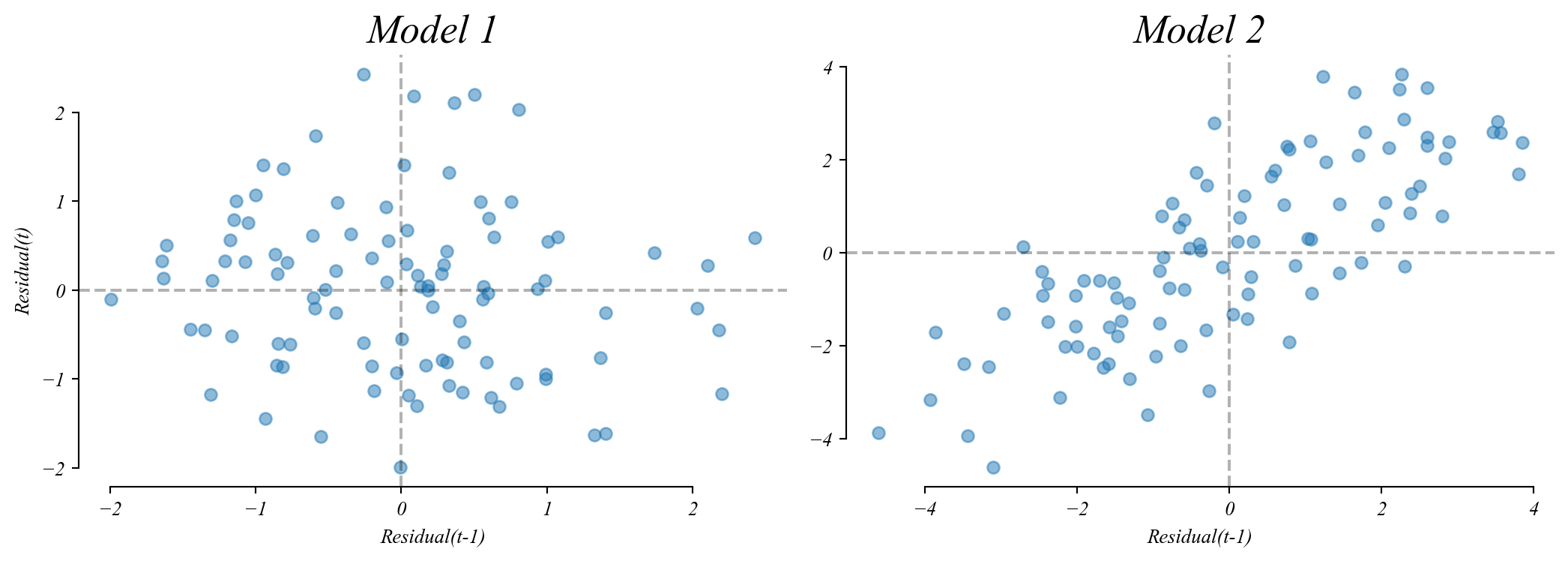
Assumption 3: Independence
Each error should be unrelated to previous errors.
Q. Which of these residual lag plots shows independence?
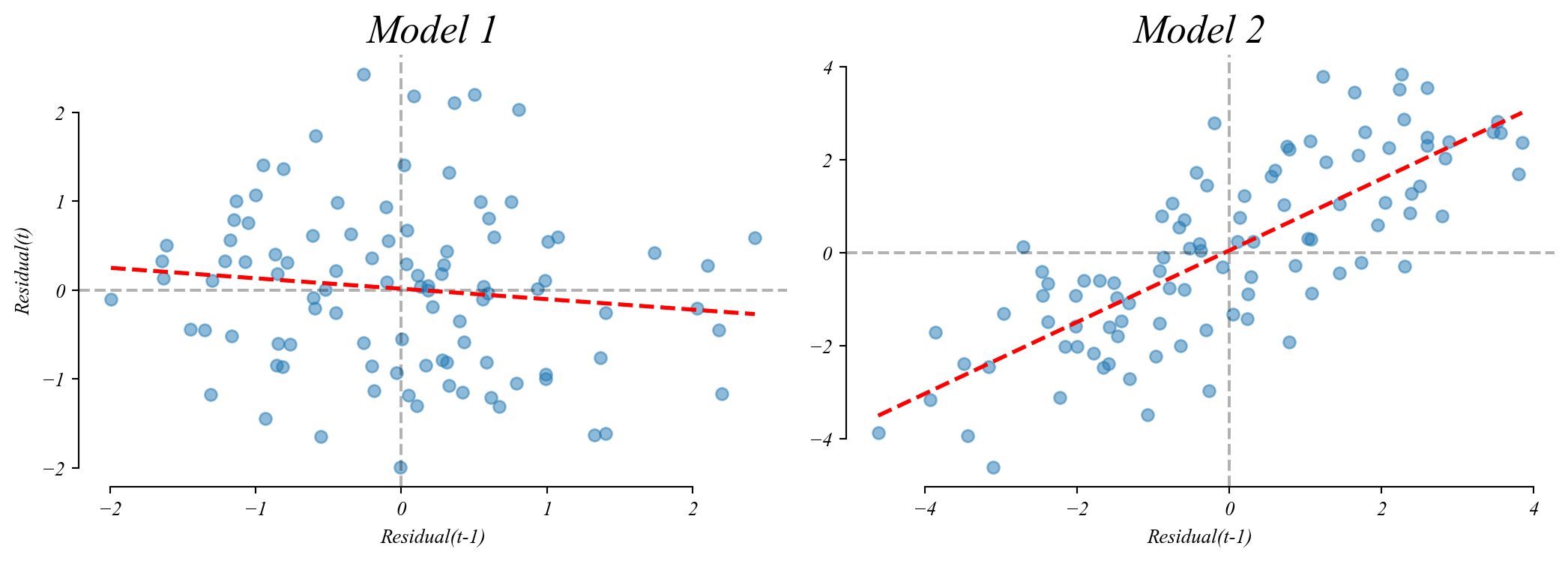
Model 1 has no (meaningful) relationship between consecutive residuals.
Model 2 shows a positive relationship (autocorrelation).
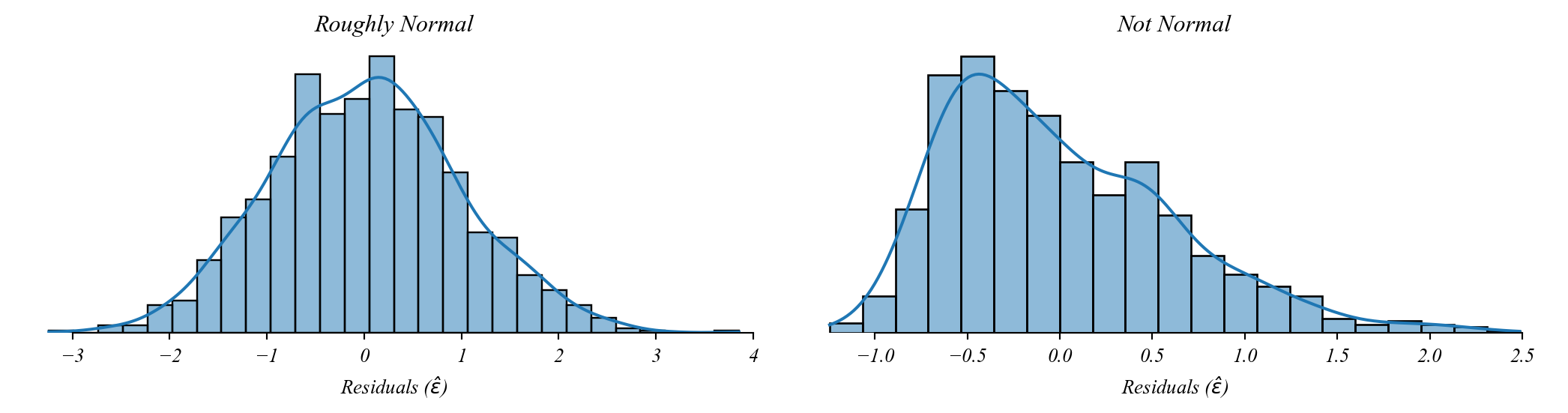
Assumption 4: Normality
Residuals should be normally distributed.
By the CLT we can still use GLM without this so long as the sample is large.