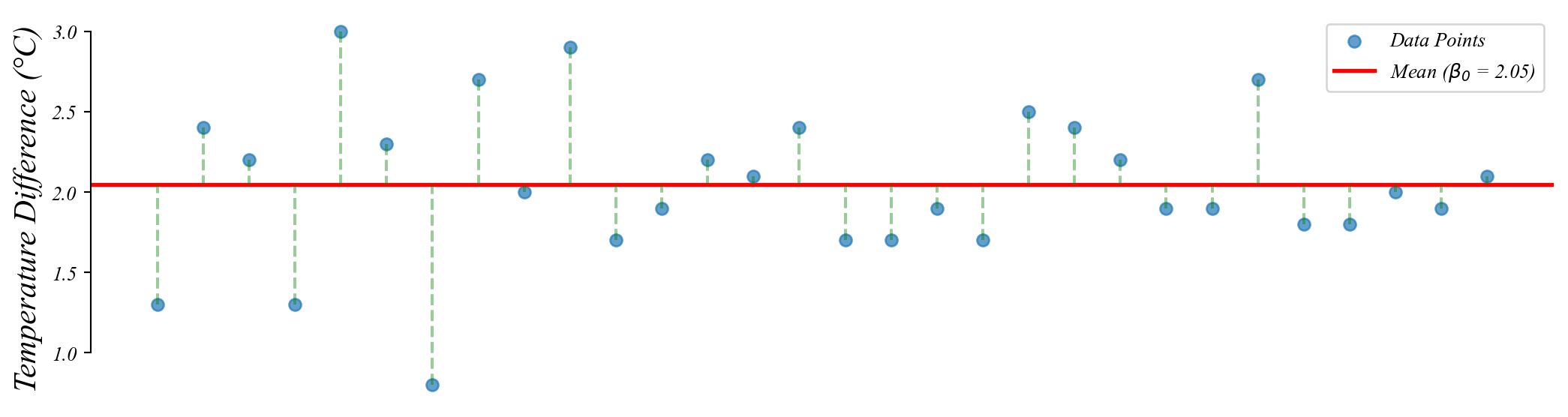
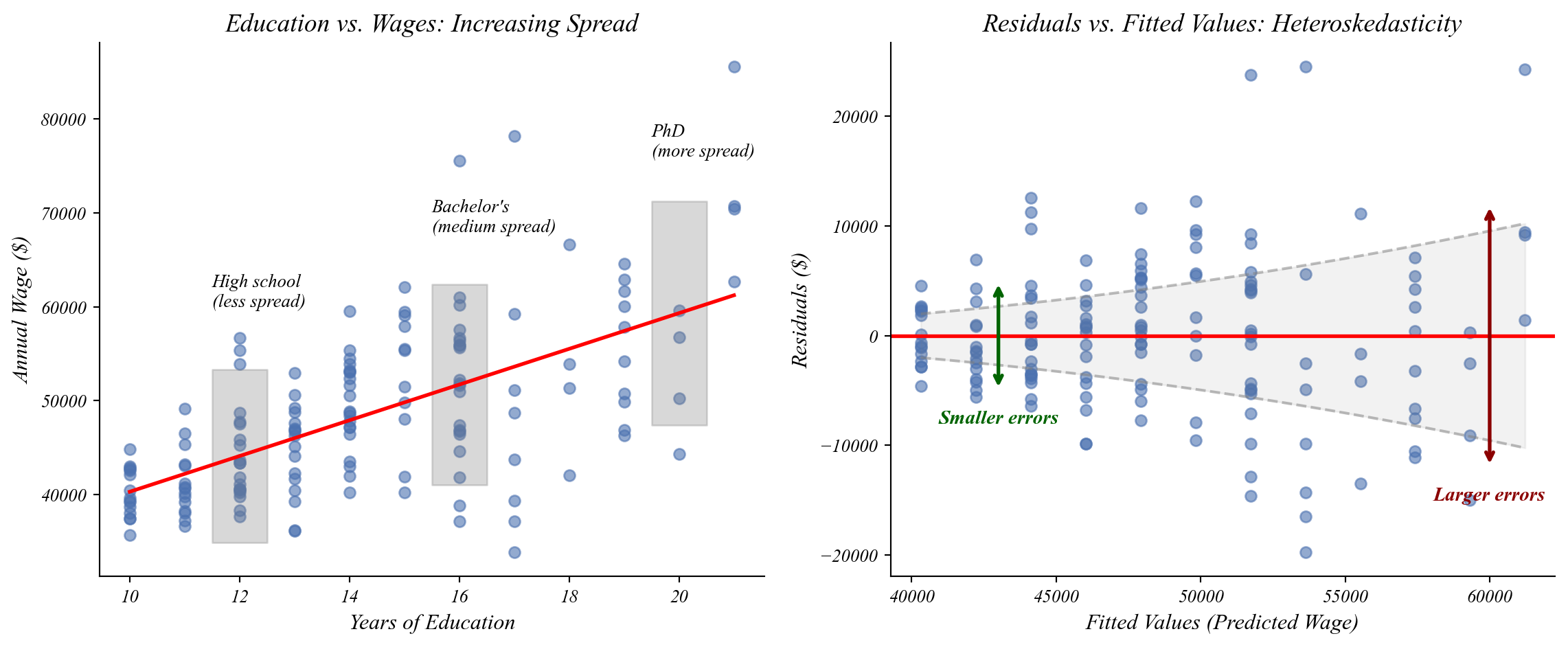
GLM: City Greenspace and Temperature
Q. Is temperature lower in neighborhoods with more green space?
What is the variable type of High Greenspace?
Q. Does temperature change as we increase by one on the horizontal axis?
\[Temperature = \beta_0 + \beta_1 \cdot HighGreen + \varepsilon\]
GLM: City Greenspace and Temperature
Q. Is temperature lower in neighborhoods with more green space?
- The GLM framework doesn’t care whether \(x\) is continuous or binary. We code the group as 0 and 1, and fit the same model.
- Like with numerical predictors, the GLM tests whether \(\beta_1\) is different from zero.
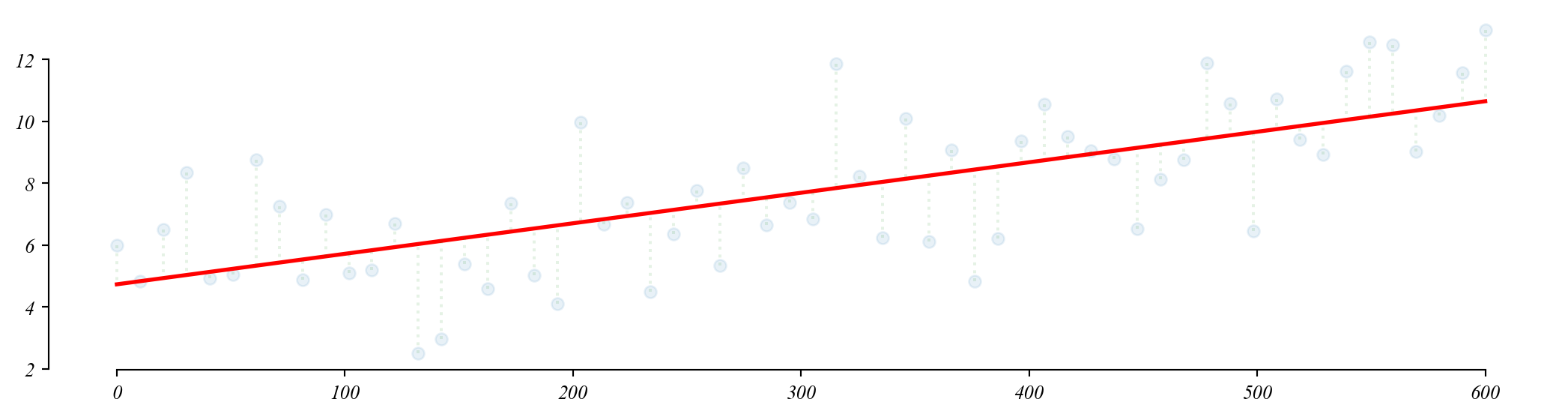
GLM: City Greenspace and Temperature
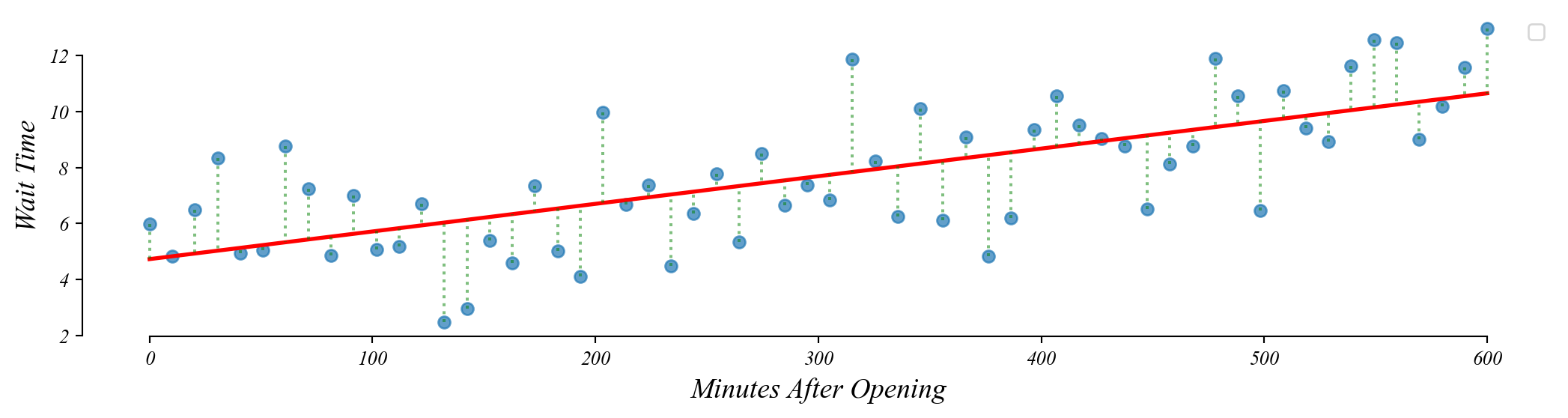
Q. Does temperature change as we move out on the horizontal axis?
\[Temperature = \beta_0 + \beta_1 \cdot HighGreen + \varepsilon\]
How would we interpret \(\beta_0\) here?
> \(\beta_0\) is the mean temperature in (\(x=0\)) low green space cities (22.03°C)
GLM: City Greenspace and Temperature
Q. Does temperature change as we move out on the horizontal axis?
\[Temperature = \beta_0 + \beta_1 \cdot HighGreen + \varepsilon\]
How would we interpret \(\beta_1\) here?
> Cities with Green Space (x=1) have a temperature that is lower by \(\beta_1\)
> ie. a one unit increase in \(x\) changes temperature by \(\beta_1\)
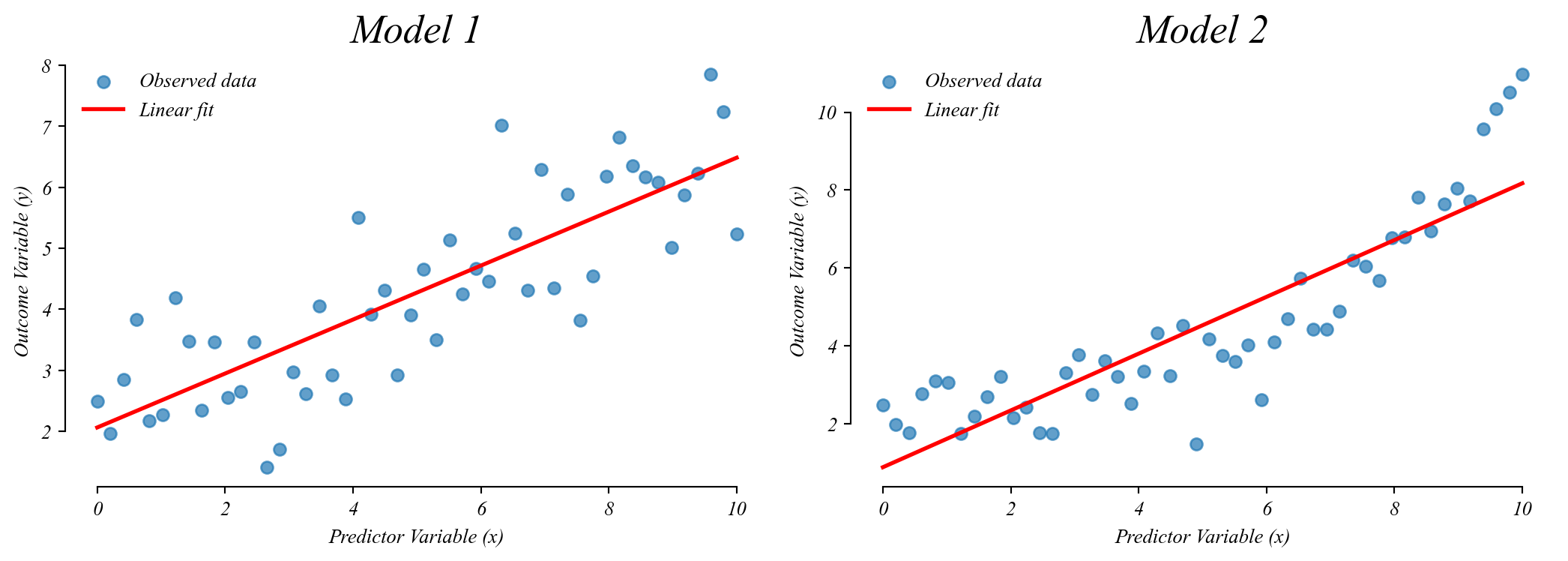
Categorical GLM: sampling error
Like before, if we take many samples, we get slightly different slopes and slightly different fits.
Categorical GLM: sampling distribution of slopes
The slope coefficient follows a normal distribution centered on the population difference.
> the slopes follow a normal distribution around the population difference!
> this lets us perform a t-test on the slope!
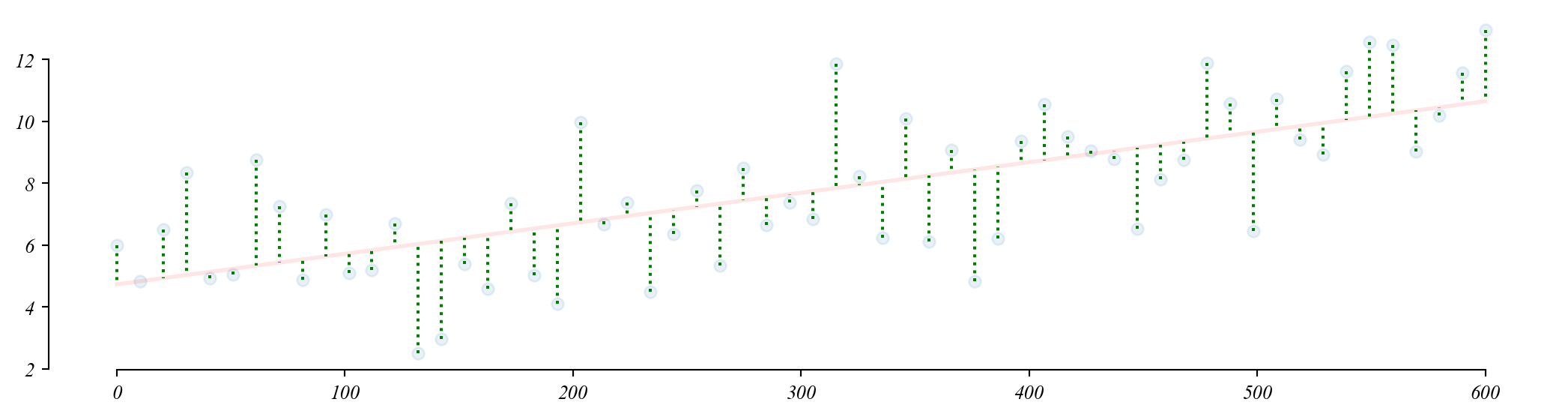
Categorical GLM: sampling distribution of slopes
The slope coefficient follows a normal distribution centered on the population difference.
> we don’t know the entire distribution, just our sample slope
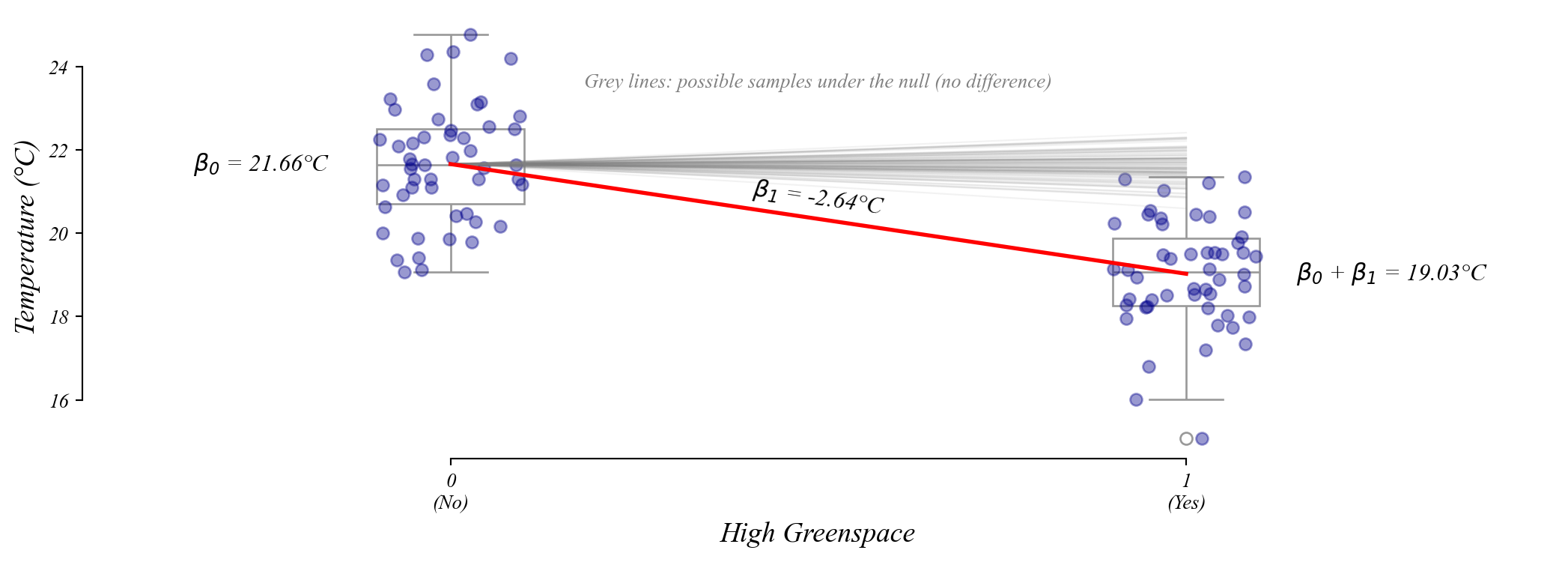
Categorical GLM: sampling distribution of slopes
The slope coefficient follows a normal distribution centered on the population difference.
> center the distribution on our null
> check the distance from the sample
Categorical GLM: sampling distribution of slopes
The slope coefficient follows a normal distribution centered on the population difference.
> p-value: the ‘surprisingness’ of our sample if \(\beta_1 = 0\)
> the probability of seeing our sample by chance if there is no difference
> a small p-value is evidence against the null hypothesis (\(\beta_1 = 0\))
Categorical GLM: null slopes
Many possible slopes we might observe by chance if the null (\(\beta_1 = 0\)) were true.
> how likely does it look like this slope was drawn from the null slopes?
> p-value: the probability of a slope as extreme as ours under the null (\(\beta_1=0\))
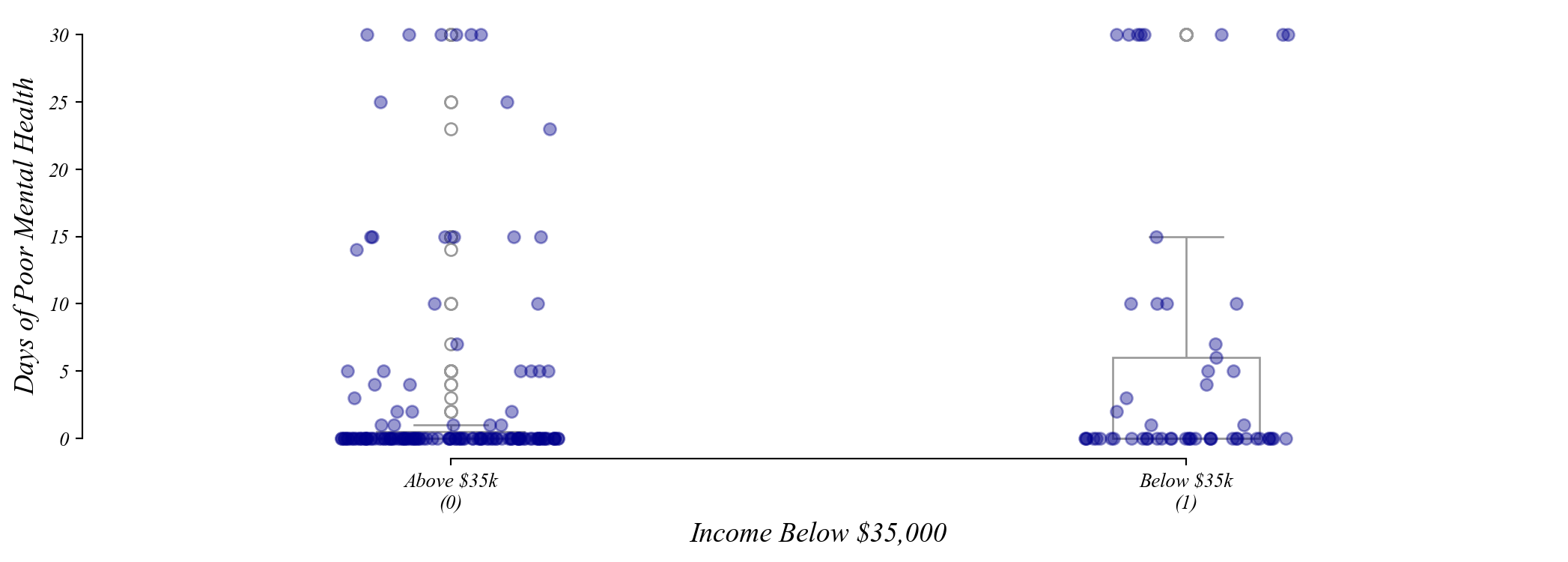
Exercise: Income and Mental Health
Do individuals earning under $35,000 report more poor mental health days?
Step 1: Summarize the data
Exercise: Income and Mental Health
Do individuals earning under $35,000 report more poor mental health days?
Step 3: Estimate the model
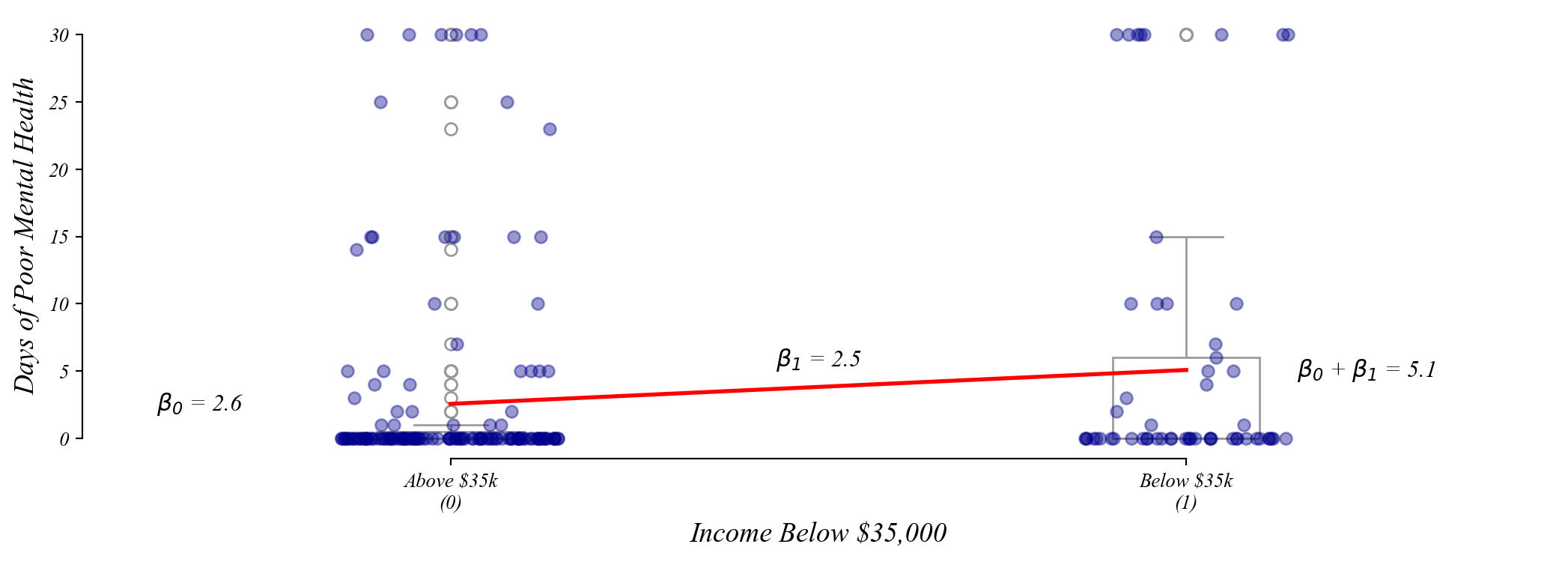
\(\beta_0\) = Mean poor mental health days for those earning above $35k
\(\beta_1\) = Additional poor mental health days for those earning below $35k
Exercise: Income and Mental Health
Do individuals earning under $35,000 report more poor mental health days?
Step 5: Interpret and communicate the findings
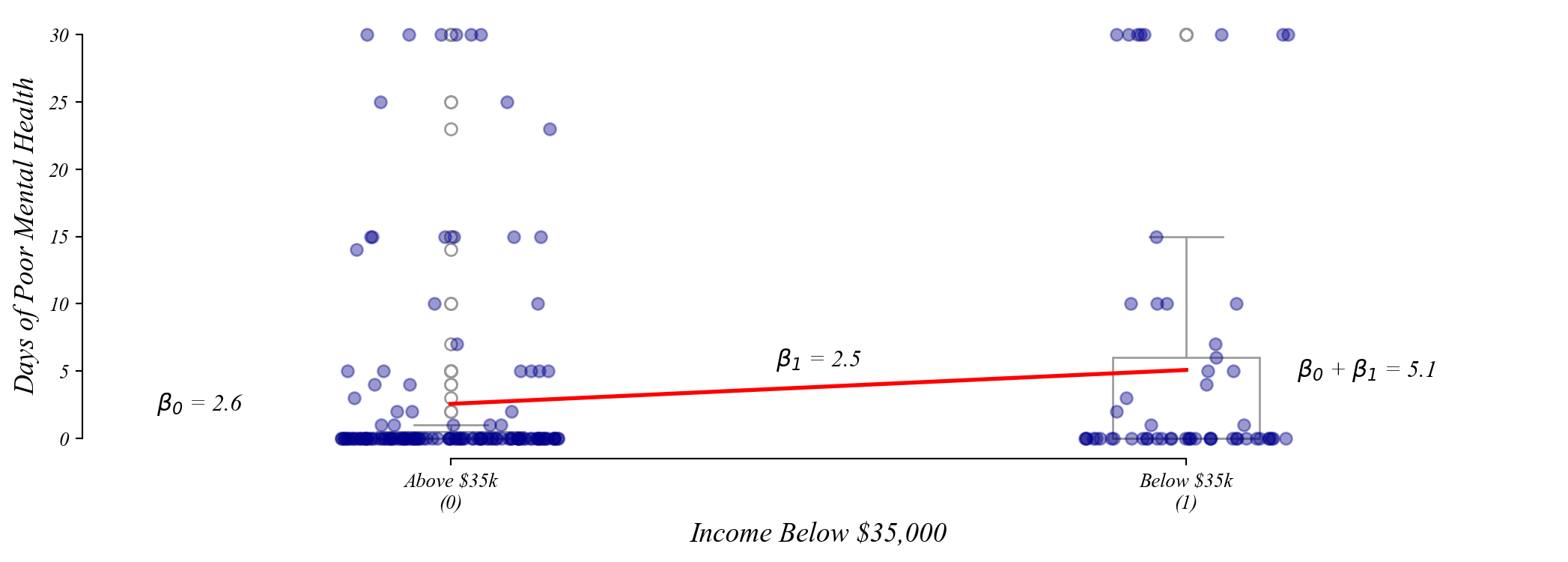
> A significant positive \(\beta_1\) suggests those earning under $35k report more poor mental health days per month
> but does low income cause poor mental health, or are other factors at play?