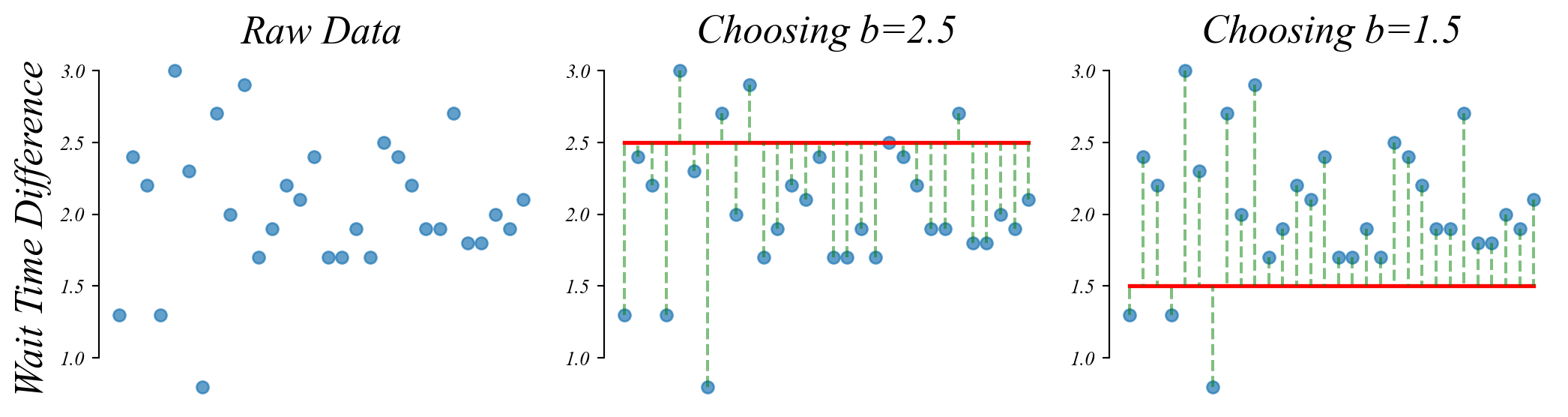
GLM: Line Fitting and the Sample Mean
The sample mean minimizes the MSE.
We minimize the MSE by choosing \(b\) to be equal to the sample mean \(\bar{y}\).
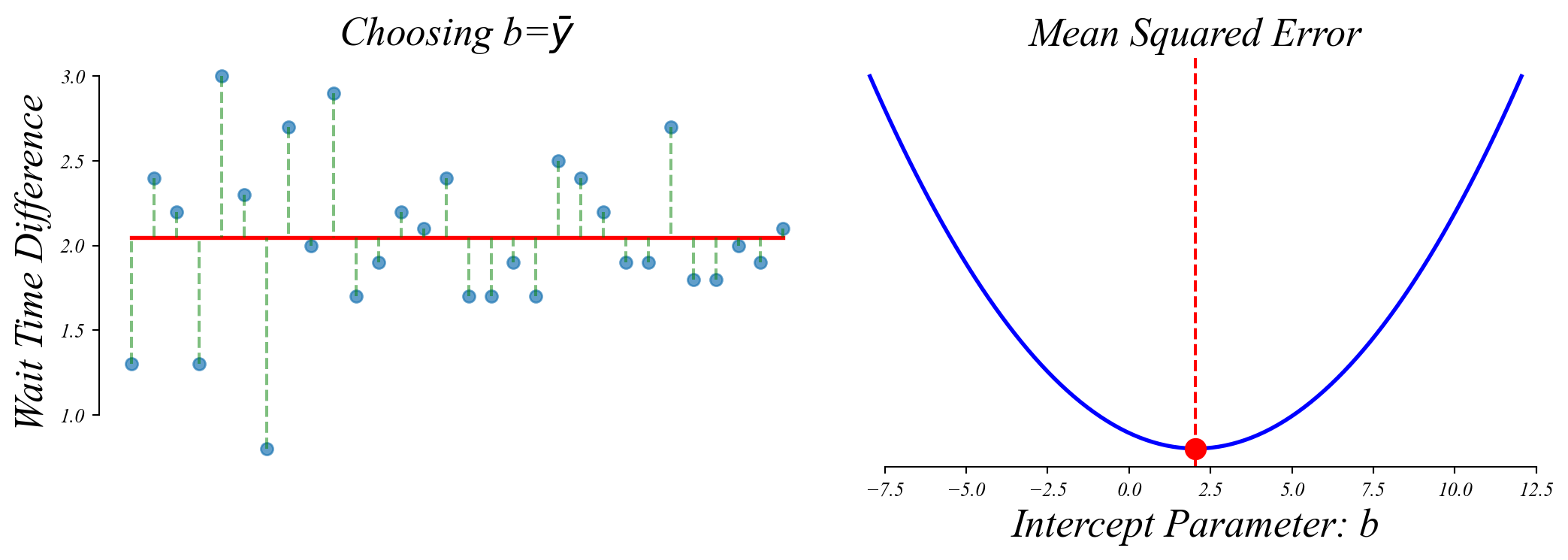
> when we’ve minimized MSE, it’s equal to the Variance!
GLM: Sampling Error and Line Fitting
Like before, if we take many samples, we get slighly different means and slighly different fits.
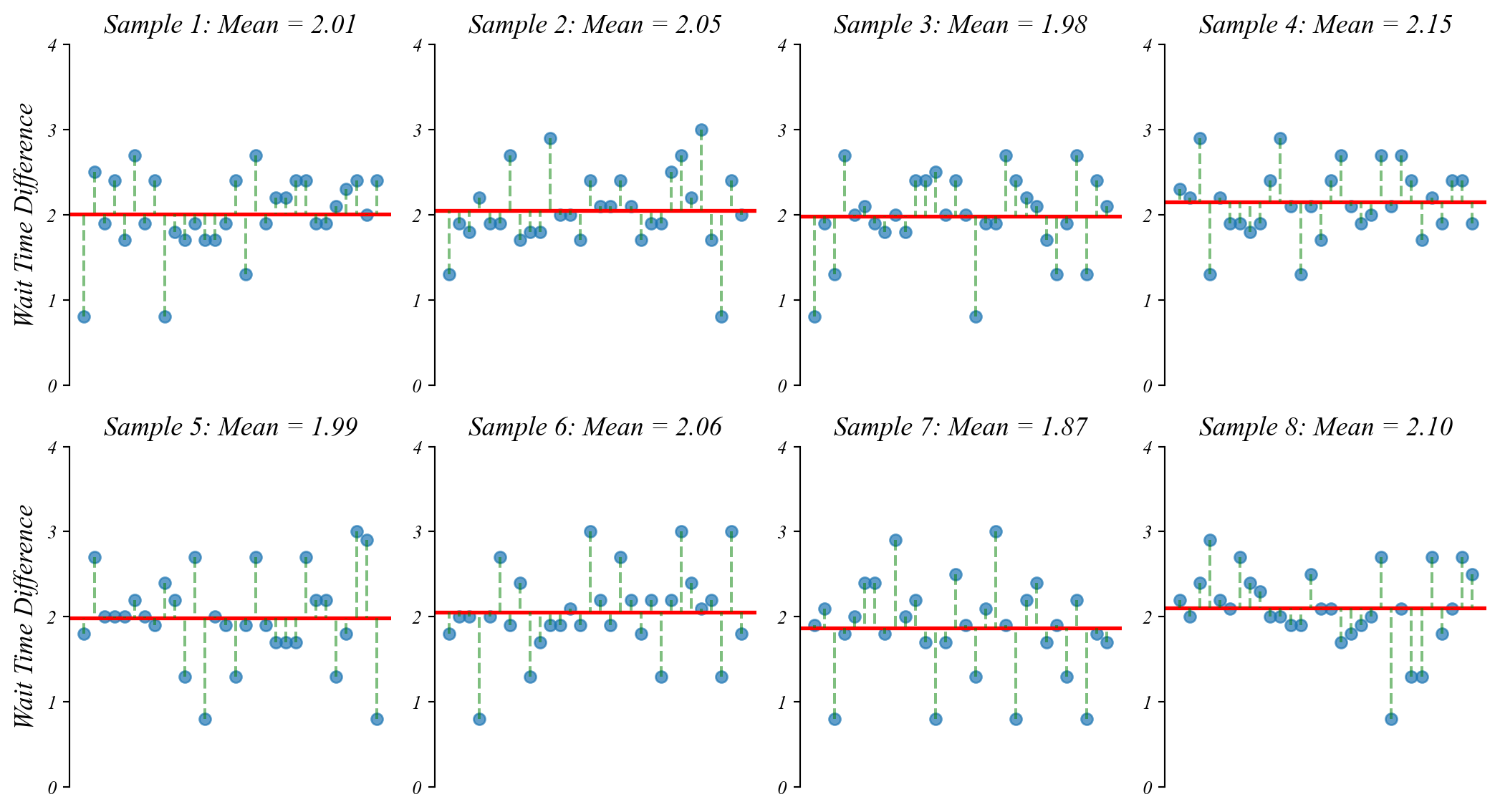
GLM: Distribution Around the Sample Mean
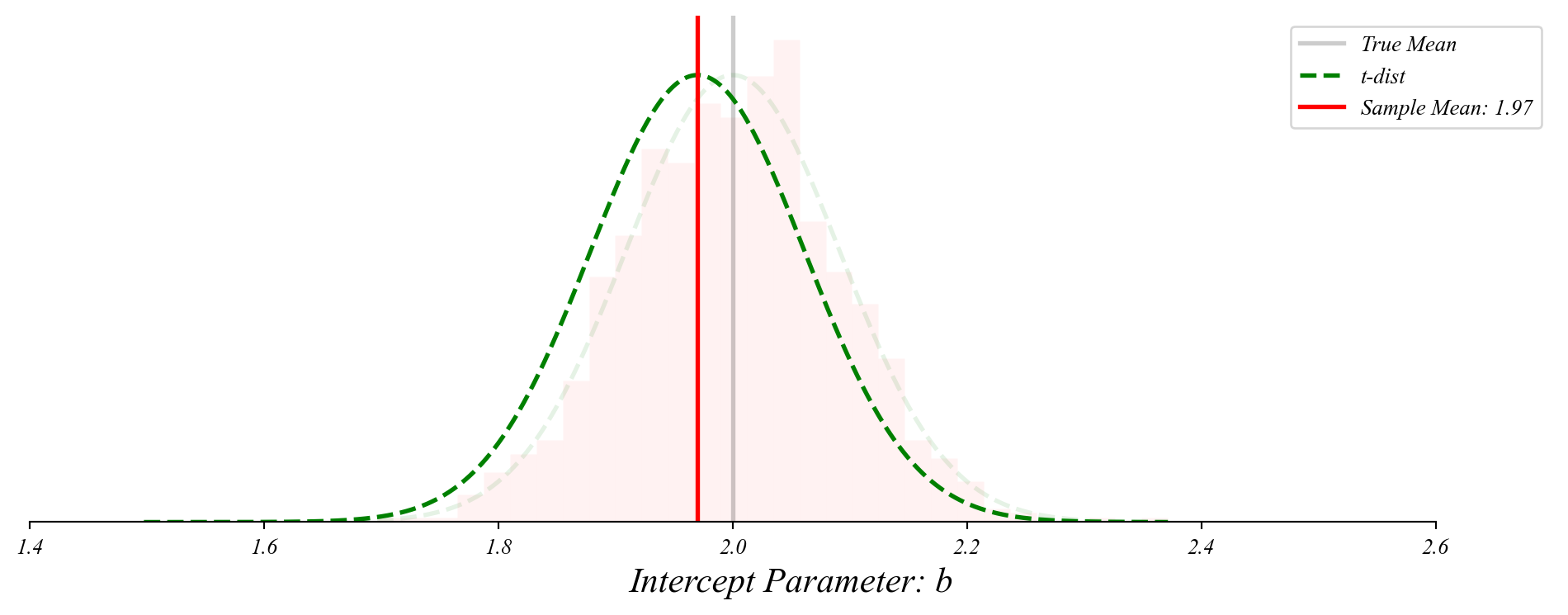
The intercept terms follow a t-distribution centered on the true mean.
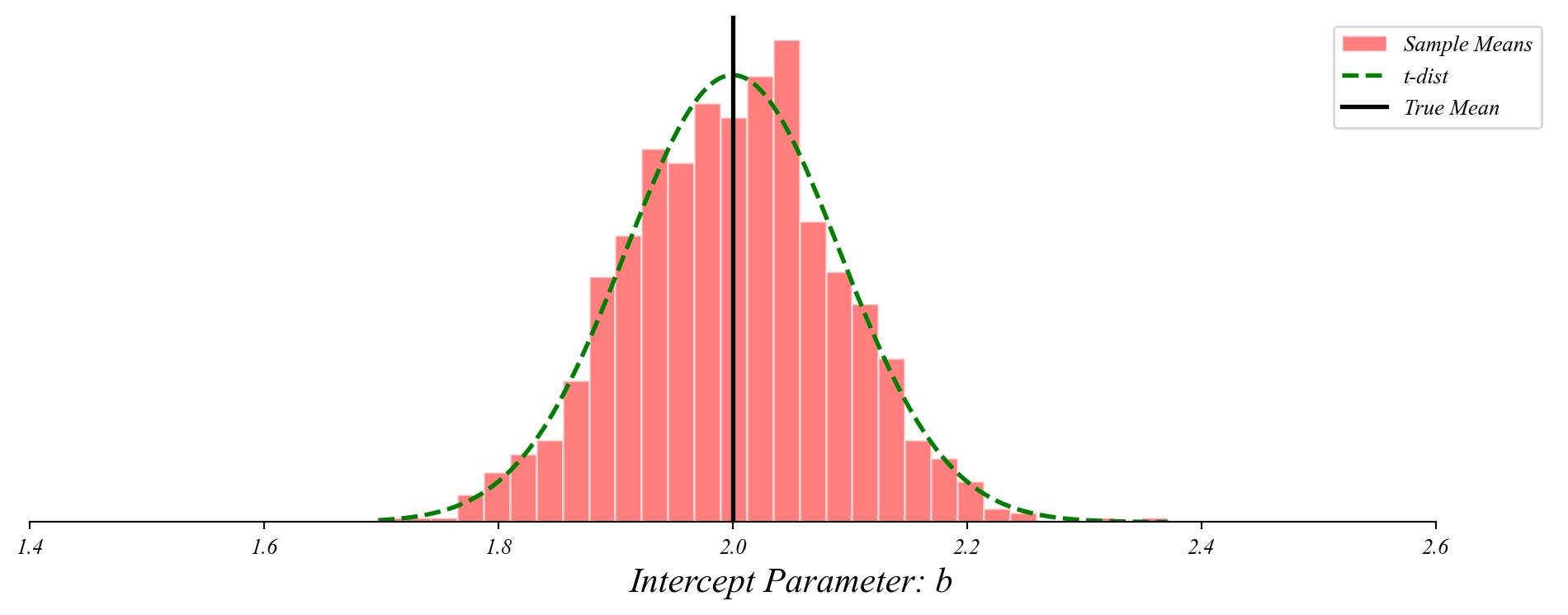
> we only observe one sample mean, so we center the distribution there
GLM: Distribution Around the Sample Mean
We center the sampling distribution on our observed sample mean.
> what is the probability of seeing this if the average wait time is 1.8 minutes?
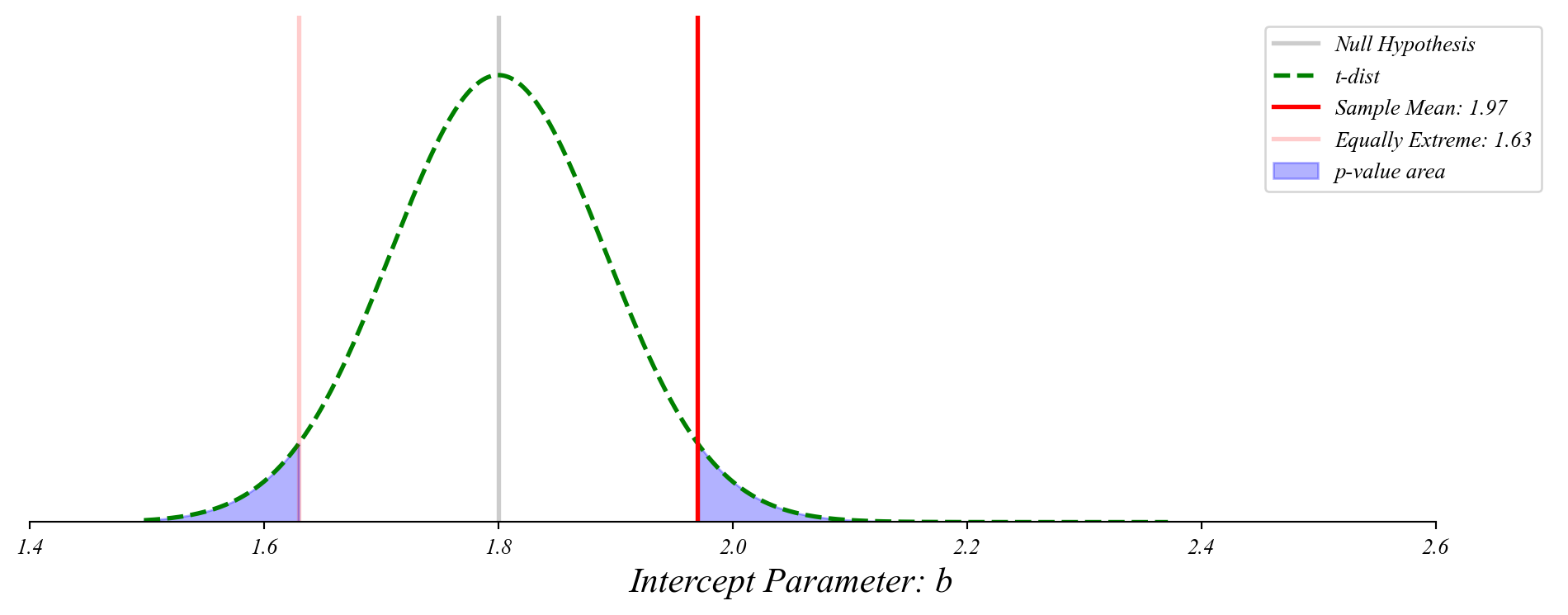
GLM: Finding p-values
The probability of something as extreme as our sample mean given the null.
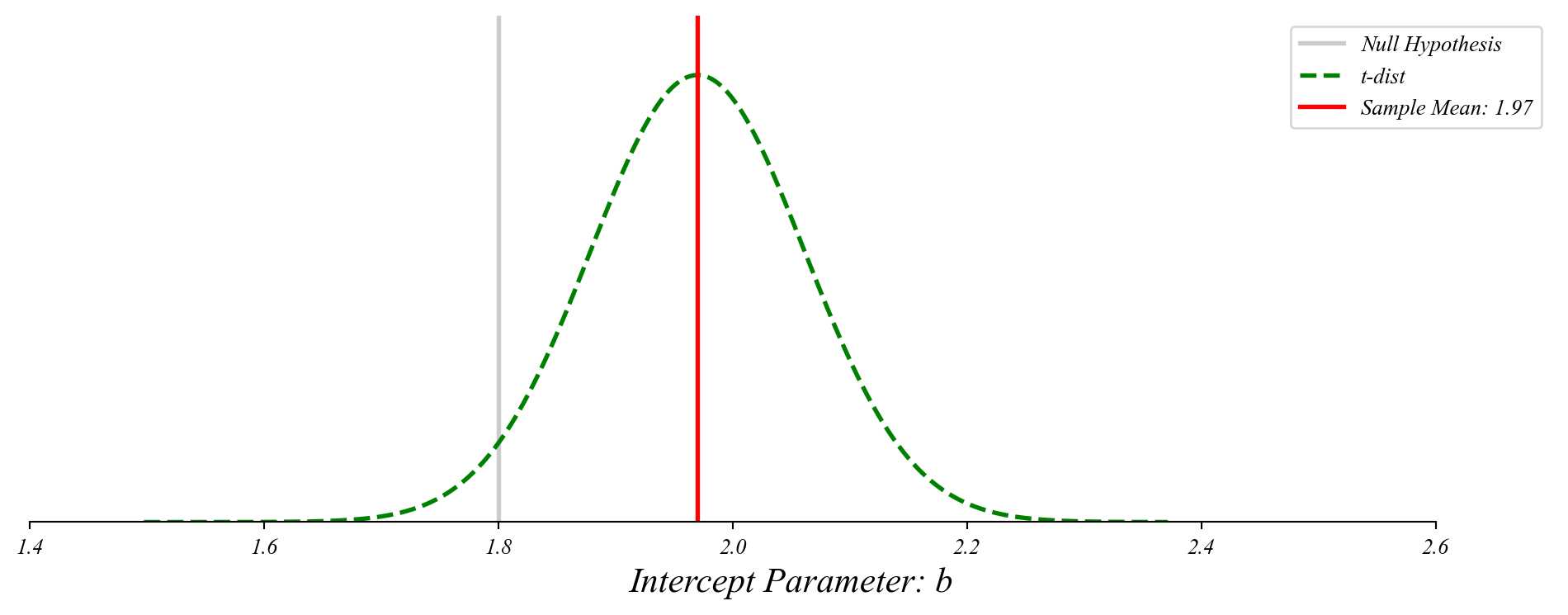
> here we’re centering the t-distribution on the observed sample mean
> as before, this is mathematically equivalent to centering on the null
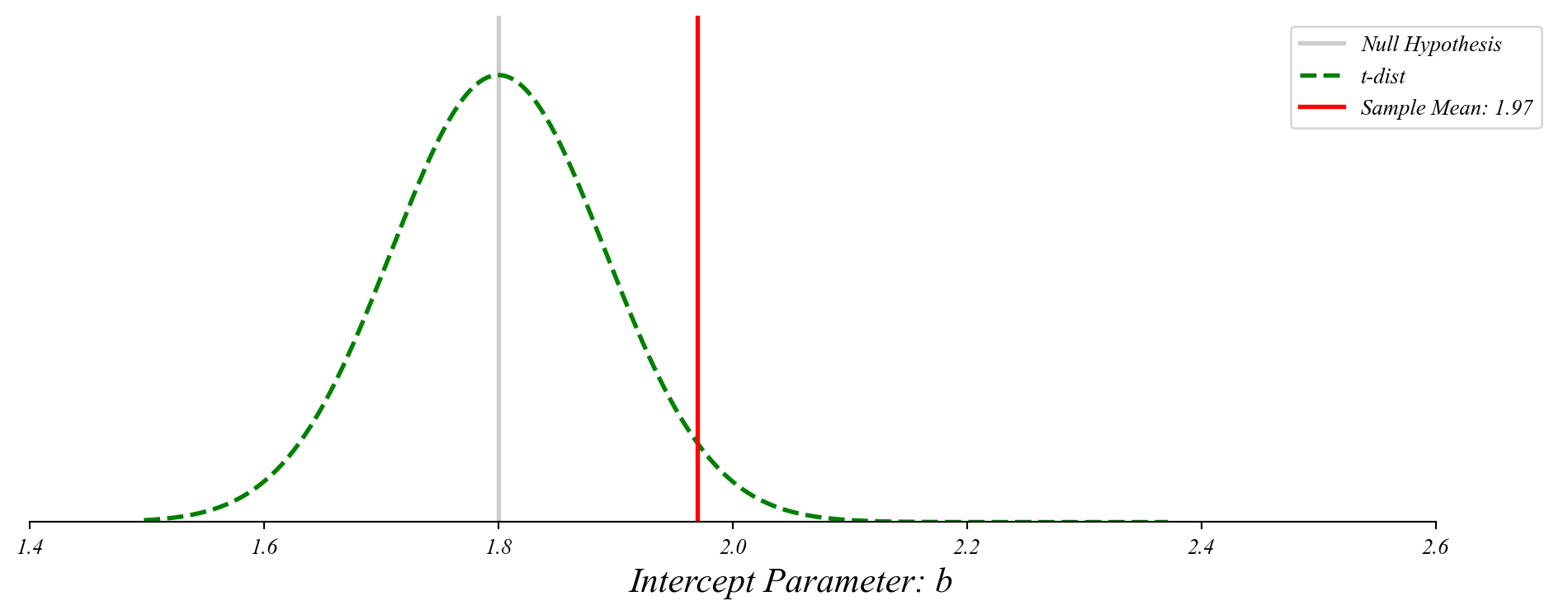
GLM: Finding p-values
The probability of something as extreme as our sample mean given the null.
GLM: Finding p-values
The probability of something as extreme as our sample mean given the null.
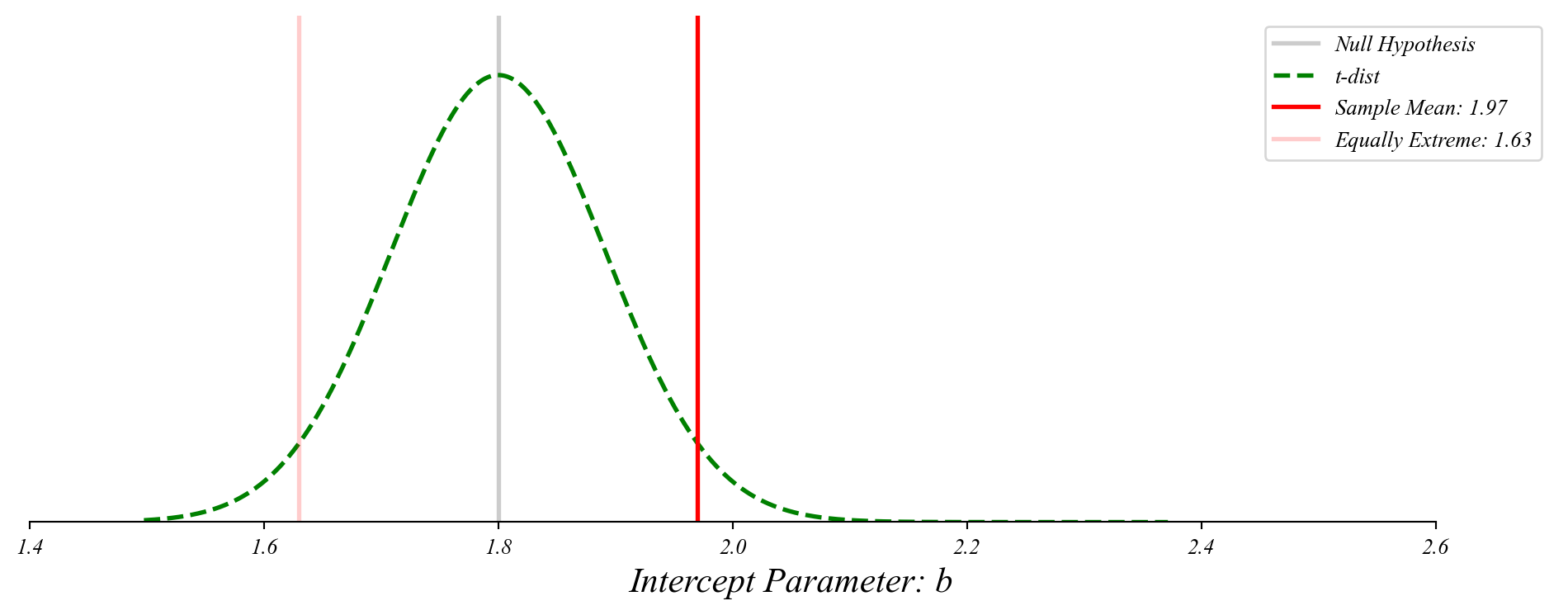
GLM: Finding p-values
The probability of something as extreme as our sample mean given the null.
GLM: Intercept Model
A t-test is a linear model with only an intercept: \(y = \beta_0 + \epsilon\)
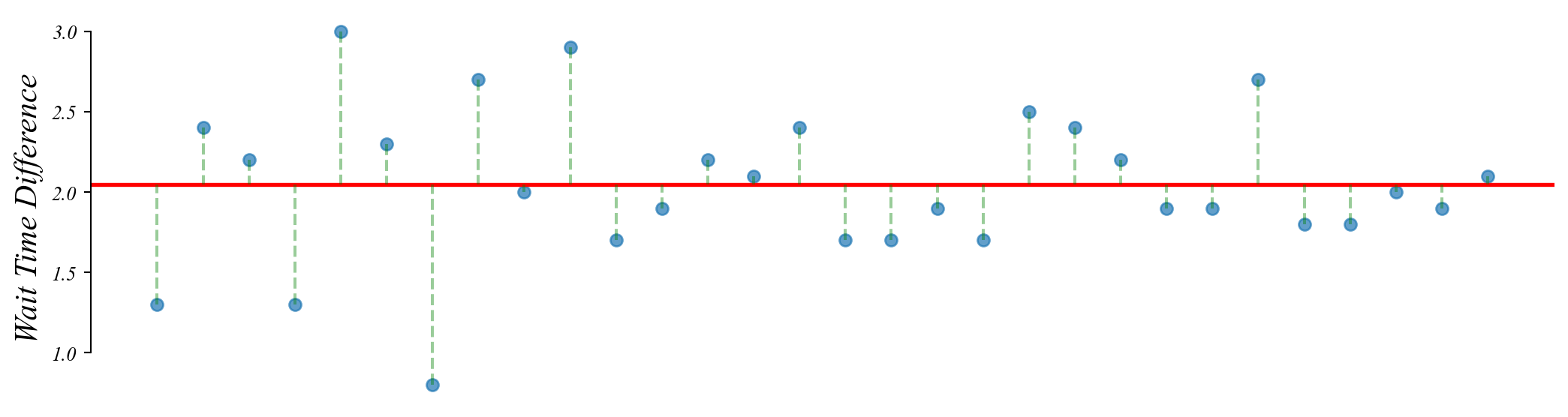
> the sample mean \(\beta_0\) minimizes the sum of squared errors
> the p-value tells us the probability of the data given the default null
> the best guess of the true mean is \(\beta_0\)
> this is the simplest version of an OLS regression model