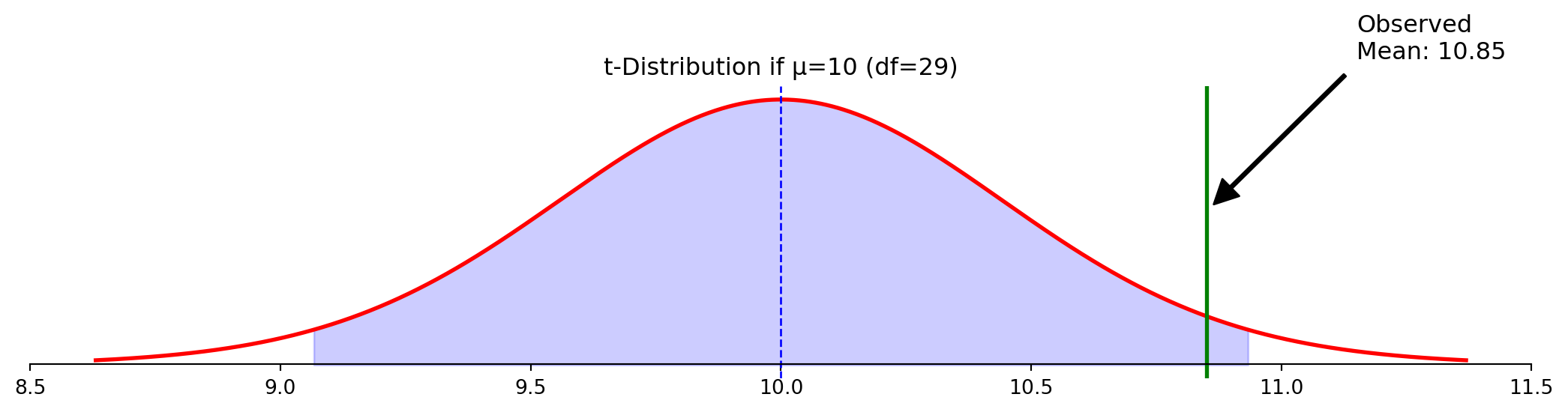
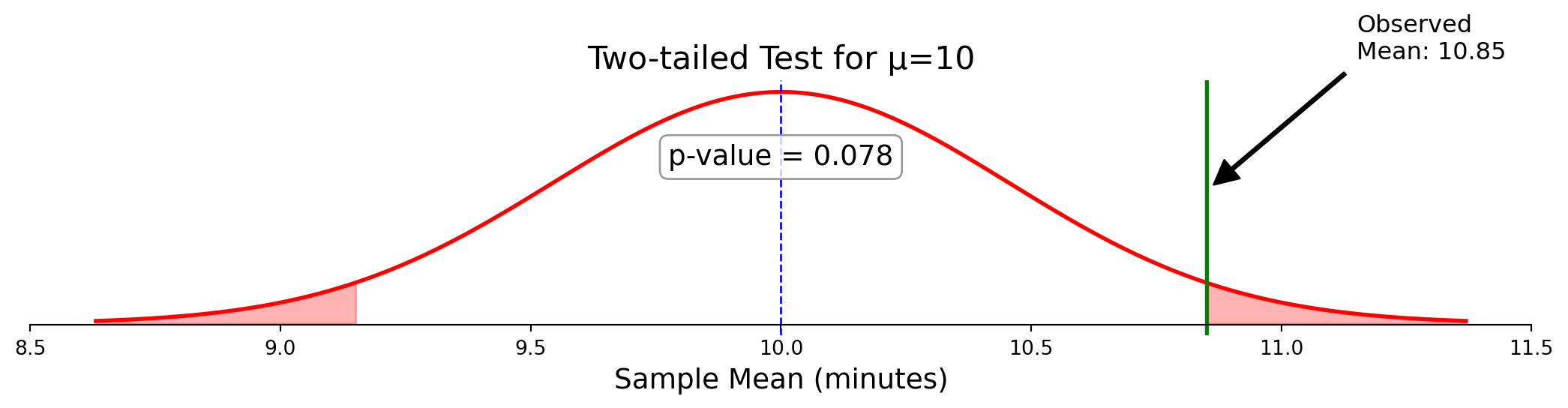
Formal rejection of the null hypothesis (p < 0.05)
Only tells us if the effect is unlikely due to chance
Practical significance:
Whether the effect size matters in the real world
A statistically significant result can still be tiny
> with large samples, even tiny differences can be statistically significant
> always consider the magnitude of the effect, not just the p-value
Common Misinterpretations
What a p-value is NOT
❌ Not: The probability that \(H_0\) is true
The p-value doesn’t tell us if the null hypothesis is correct. It assumes the null is true and then calculates how surprising our result would be under that assumption.
Example: A p-value of 0.04 doesn’t mean there’s a 4% chance the null hypothesis is true.
Common Misinterpretations
What a p-value is NOT
❌ Not: The probability that the results occurred by chance
All results reflect some combination of real effects and random variation. The p-value doesn’t separate these components.
Example: A p-value of 0.04 doesn’t mean there’s a 4% chance our results are due to chance and 96% chance they’re real.
Common Misinterpretations
What a p-value is NOT
❌ Not: The probability that \(H_1\) is true
The p-value doesn’t directly address the alternative hypothesis or its likelihood.
Example: A p-value of 0.04 doesn’t mean there’s a 96% chance the alternative hypothesis is true.
Common Misinterpretations
What a p-value is NOT
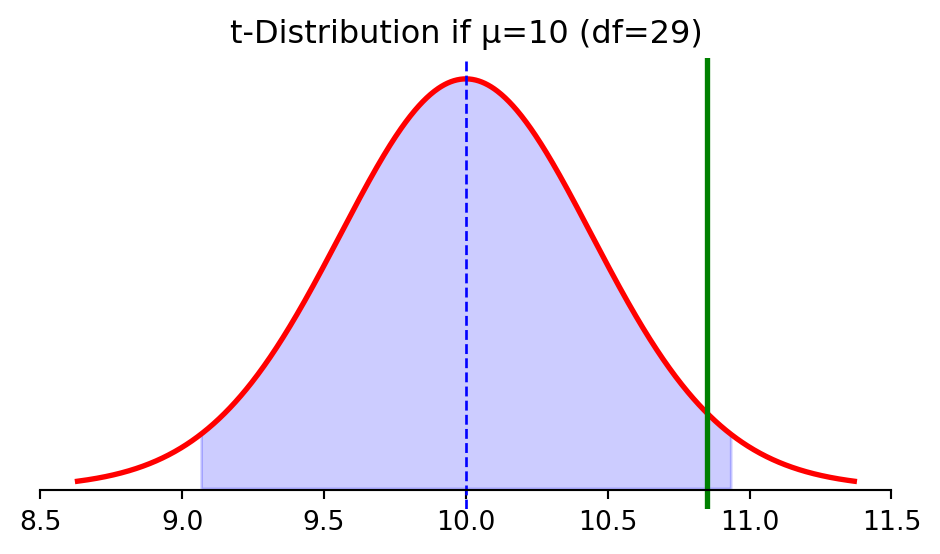
✅ Correct: The probability of observing a test statistic at least as extreme as ours, if \(H_0\) were true
It measures the compatibility between our data and the null hypothesis.
Example: A p-value of 0.04 means: “If the null hypothesis were true, we’d see results this extreme or more extreme only about 4% of the time.”
> think of it like this: The p-value answers “How surprising is this data if the null hypothesis is true?” not “Is the null hypothesis true?”
Looking Forward: Bivariate GLM
This framework extends directly to regression analysis.
Next time:
Bivariate GLM: Comparing means between two groups
> the hypothesis testing framework is foundational for modern science
Looking Forward: Regression
This framework extends directly to regression analysis.
Today’s model: \(E[y] = \beta_0\) (just an intercept)
Next:\(E[y] = \beta_0 + \beta_1 x\) (intercept and slope)
Each \(\beta\) coefficient will have its own t-test
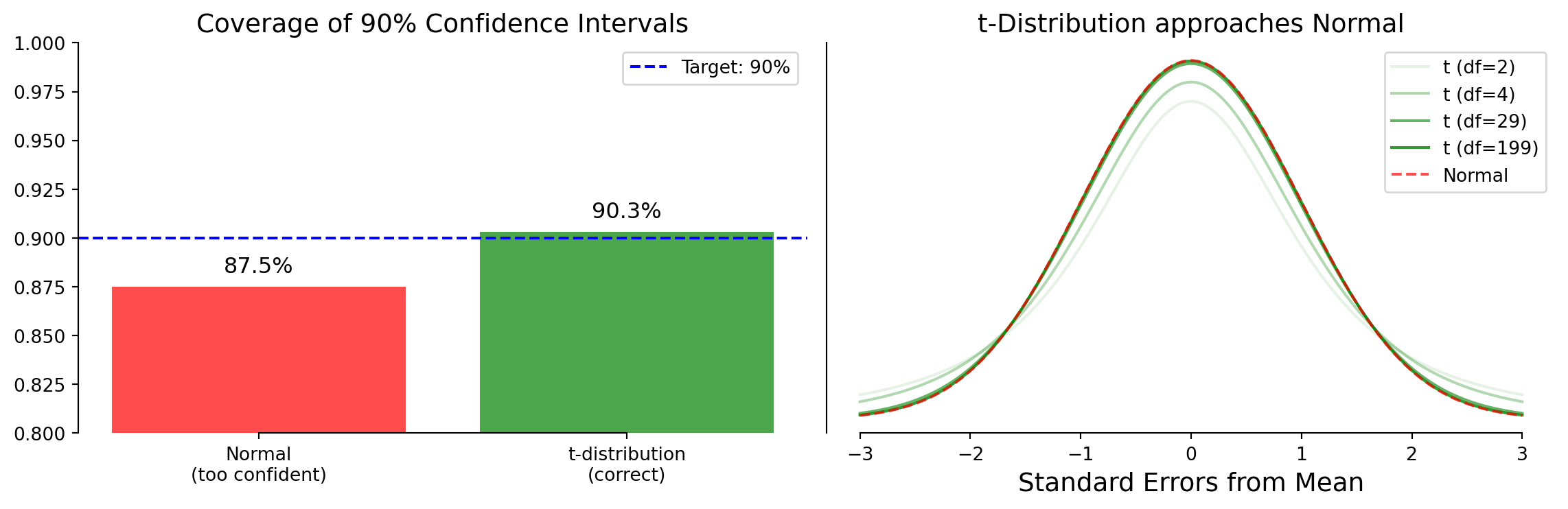
Same framework: estimate ± t-critical × SE
The t-distribution accounts for uncertainty in our estimates
> regression is just an extension of what we learned today
Summary
We’ve built the foundation for statistical modeling.
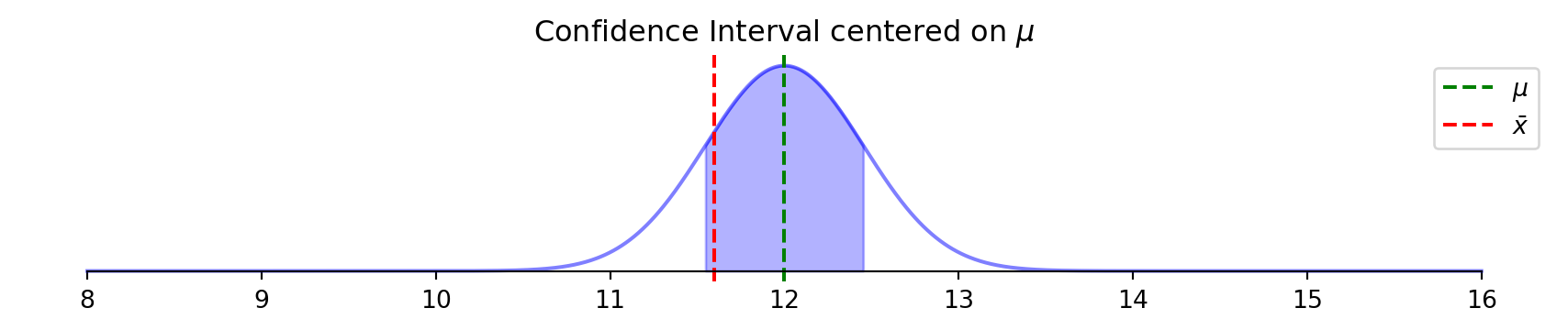
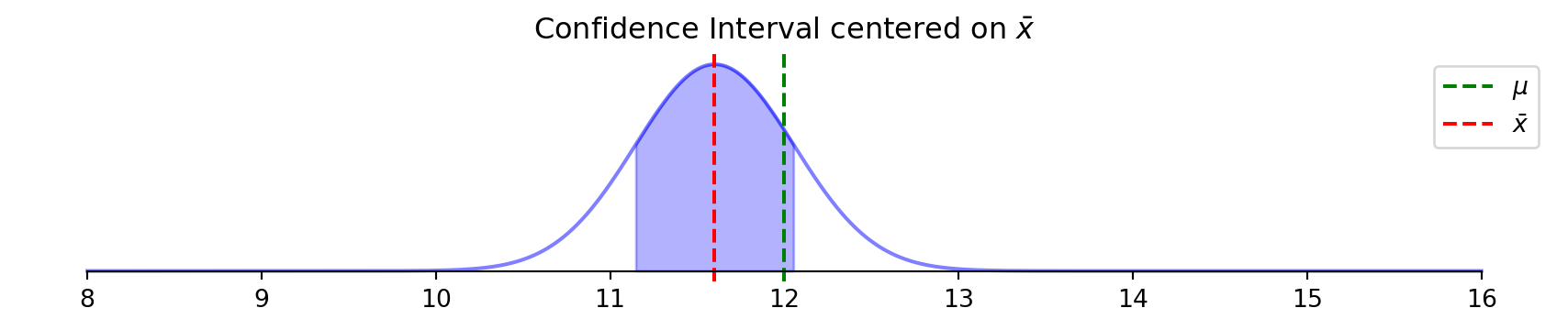
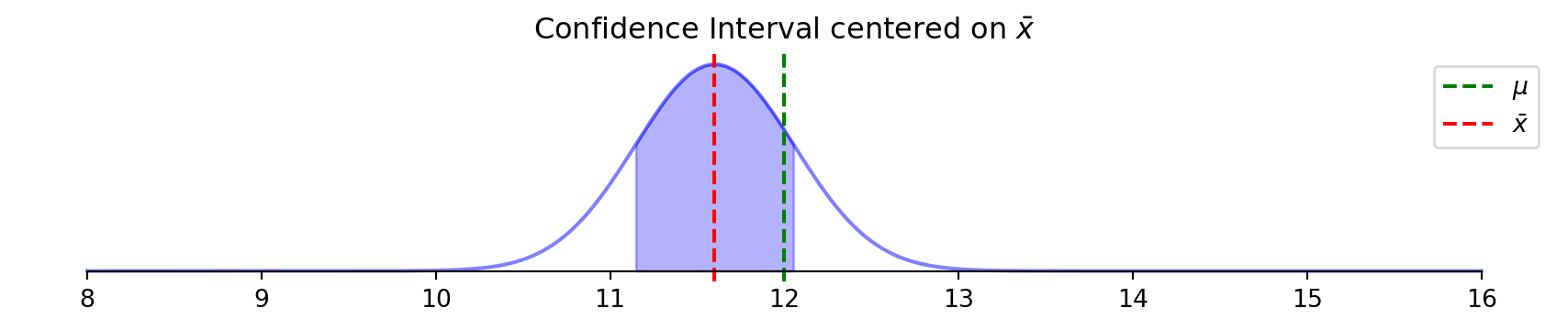
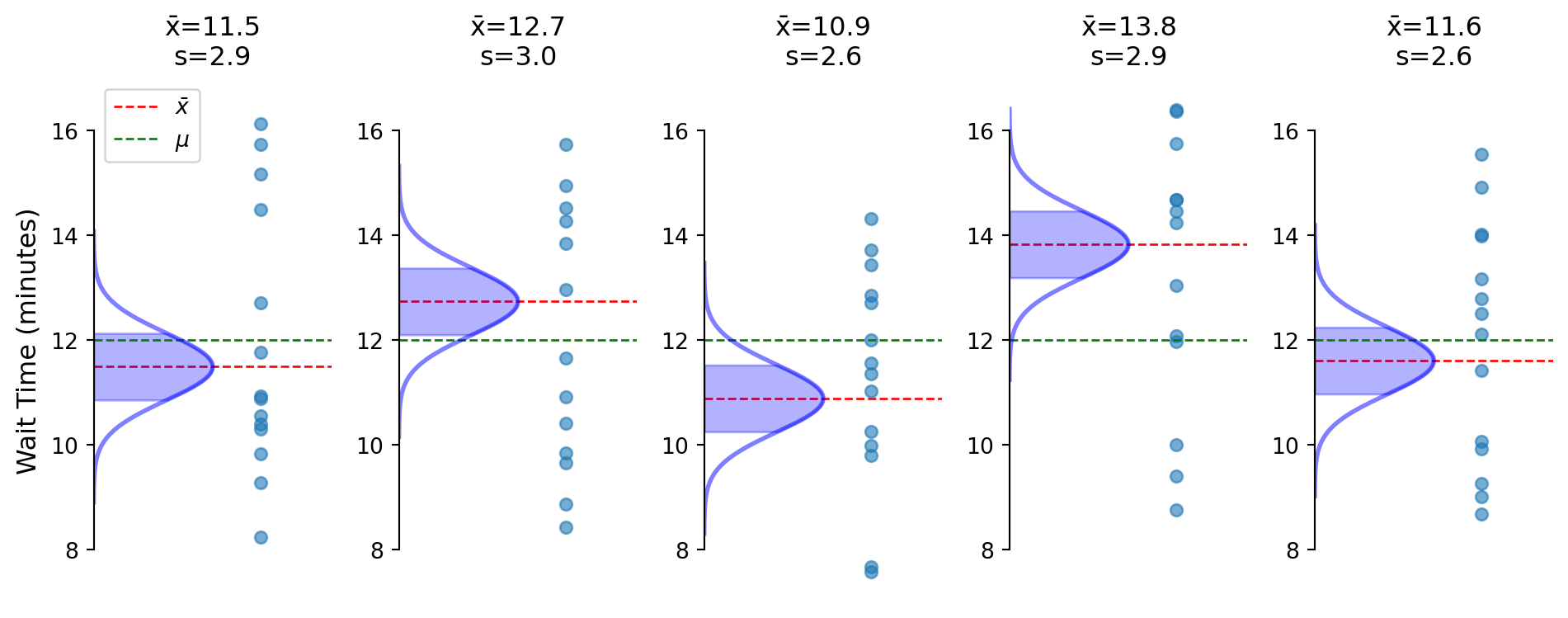
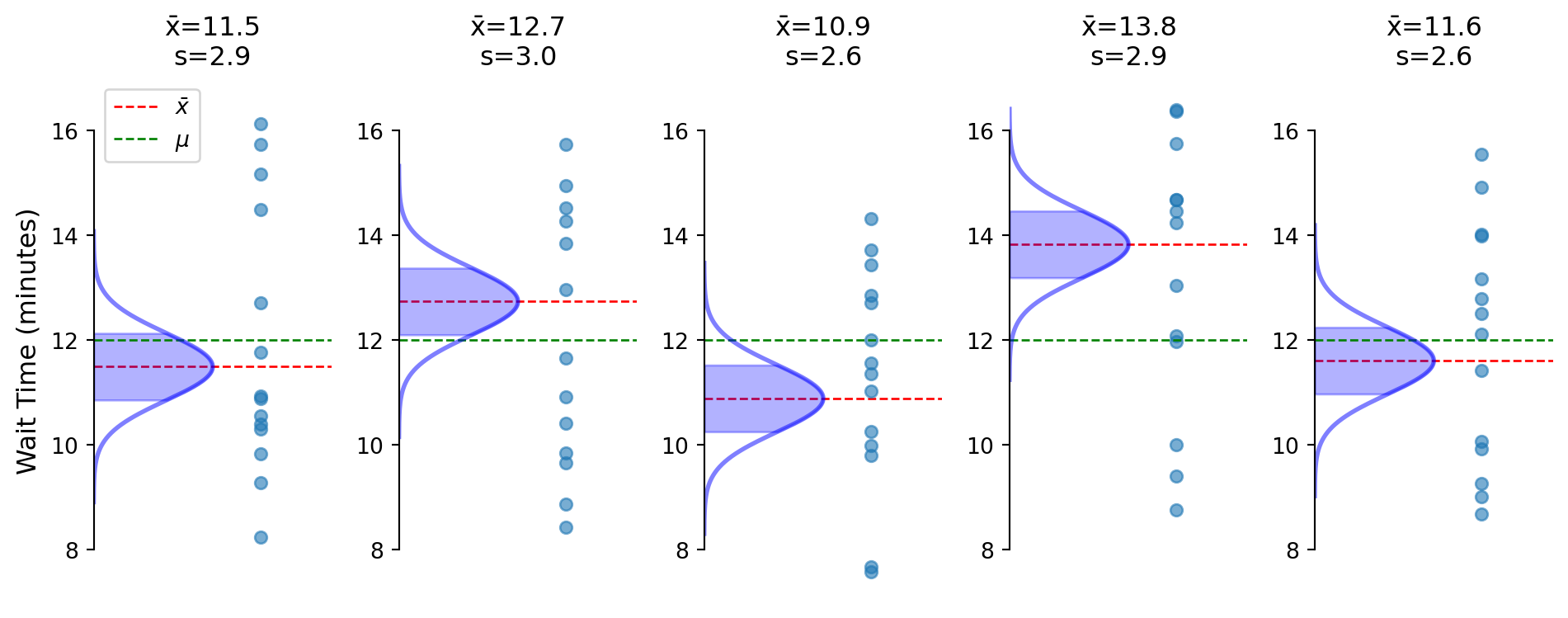
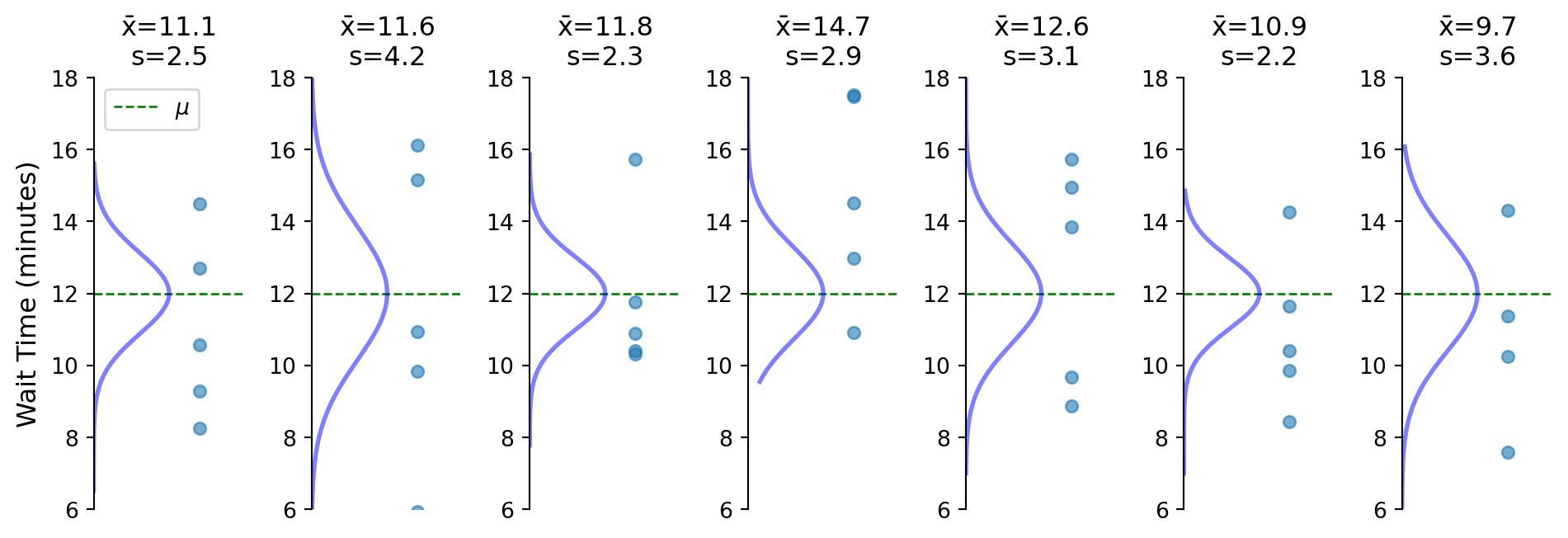
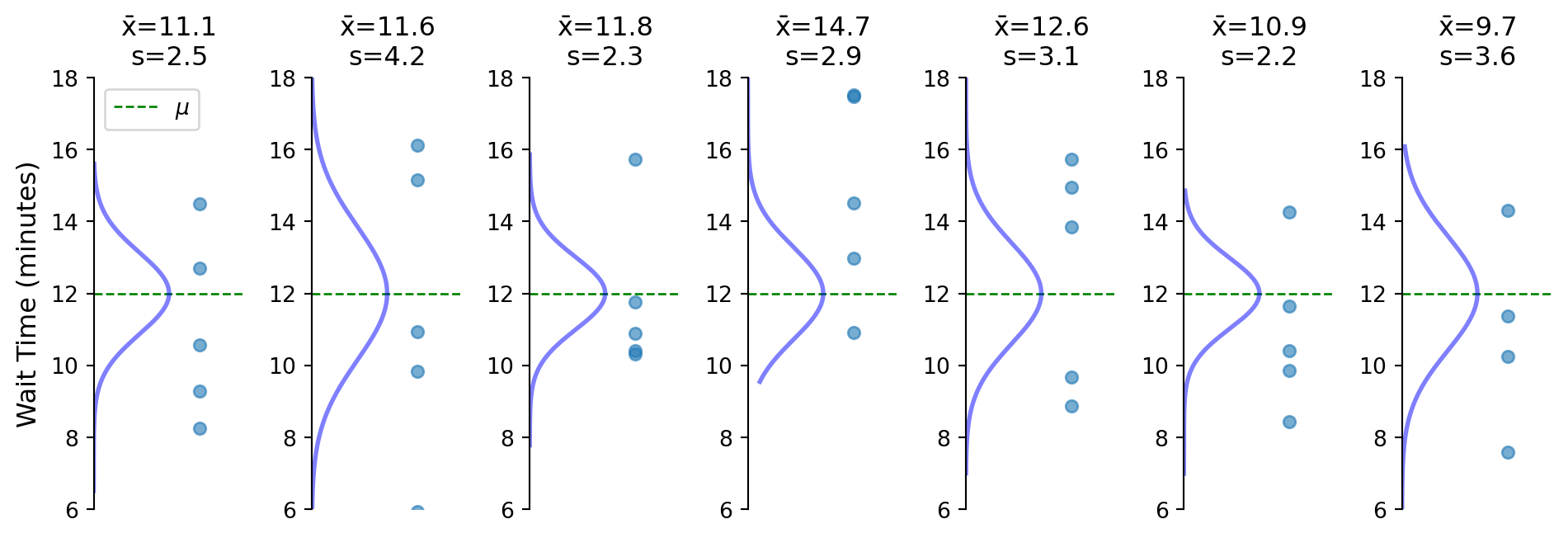
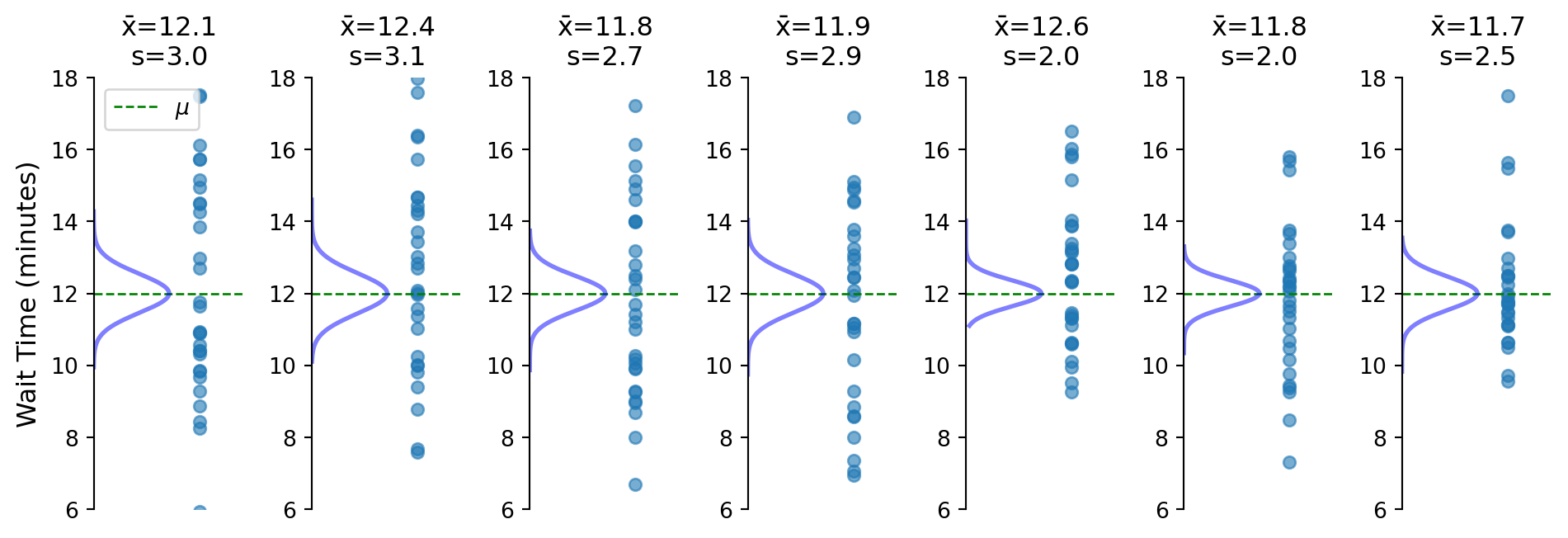
Flipped perspective: center on what we observe (\(\bar{x}\)) not what’s unknown (\(\mu\))
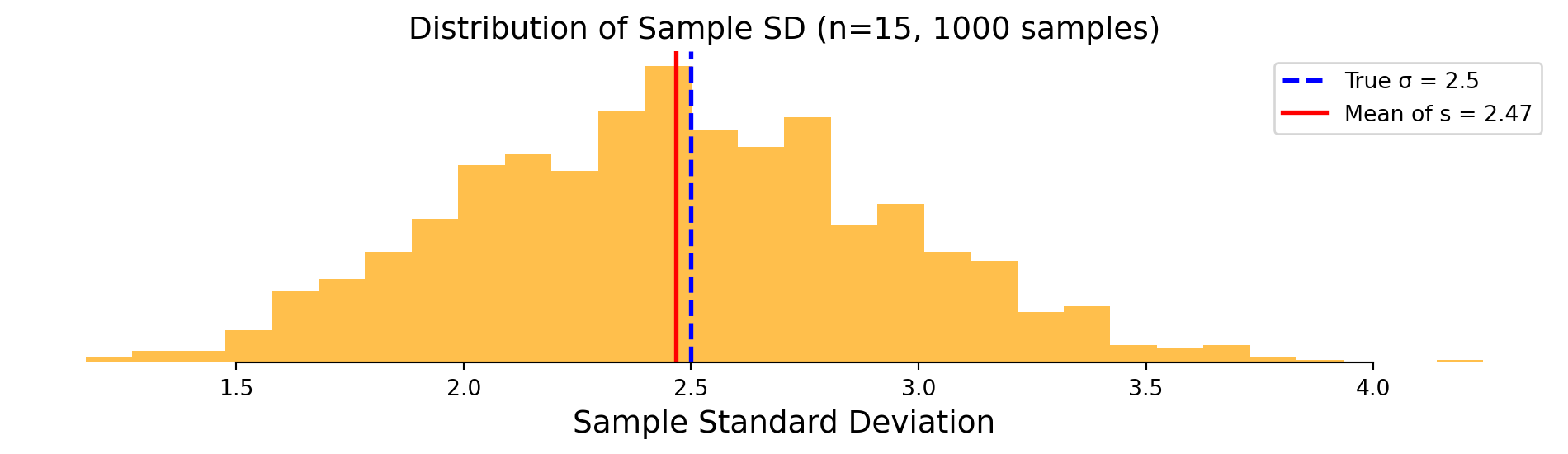
Sample SD varies, creating need for t-distribution
Built our first model: \(E[y] = \beta_0\)
Tested hypotheses by shifting data
Connected hypothesis tests to confidence intervals
> these tools form the foundation of econometric analysis