| Event | Revenue | Offer ID | |
|---|---|---|---|
| 0 | transaction | 34.56 | 2off10 |
| 1 | transaction | 18.97 | 2off10 |
| 2 | transaction | 33.90 | Bogo 5 |
| 3 | transaction | 18.01 | Bogo 10 |
| 4 | transaction | 19.11 | Bogo 10 |
Revenue by Offer Type: Boxplot
The distribution of revenue by offer type.
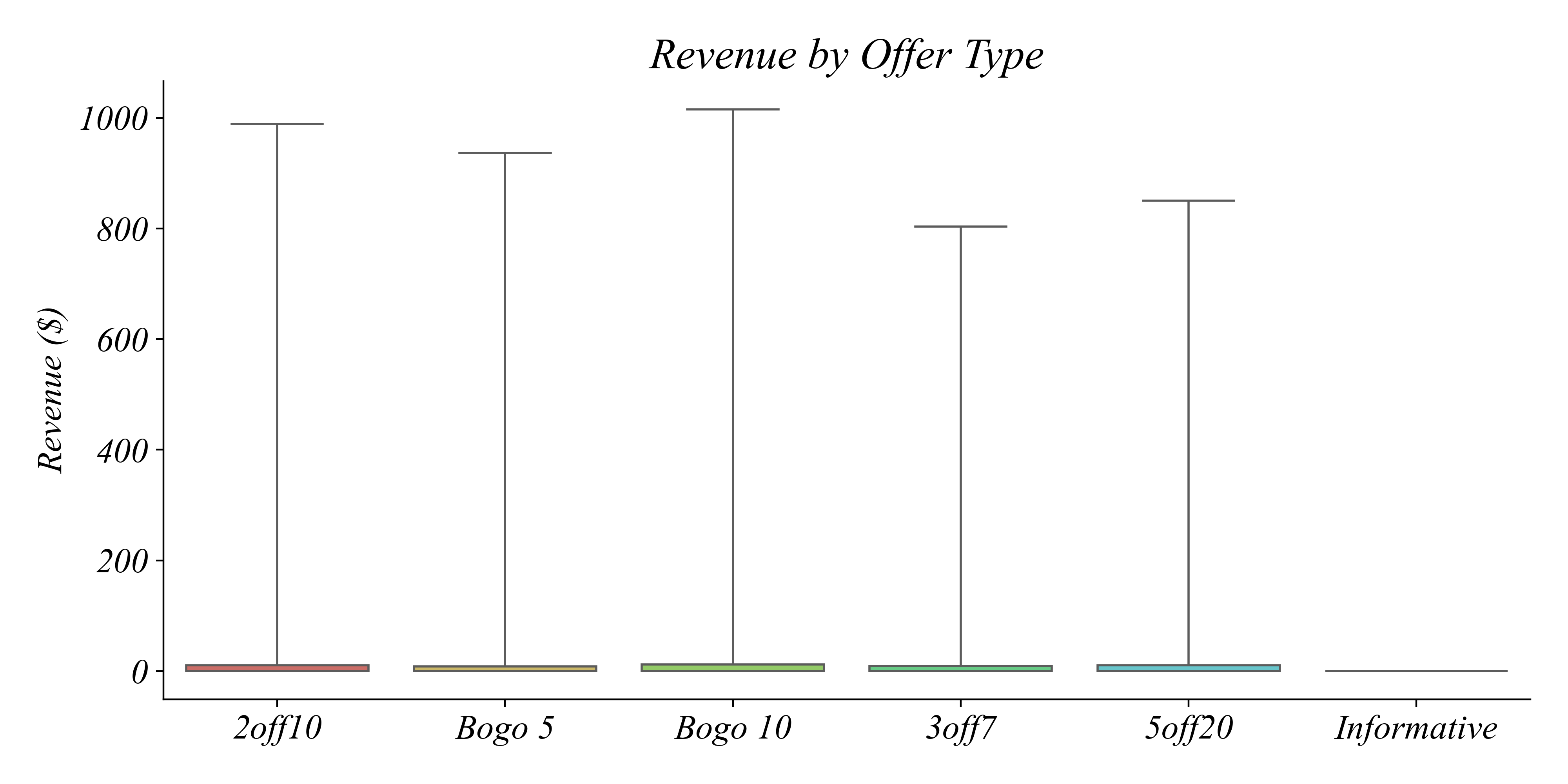
> hard to see — why are so many values compressed at zero?
Log Transformation: Visualized
The transformation spreads out skewed data
> x-axis is compressed at low values; y-axis spreads them out evenly
Log Revenue by Offer Type: Boxplot
Now we can see the data better.
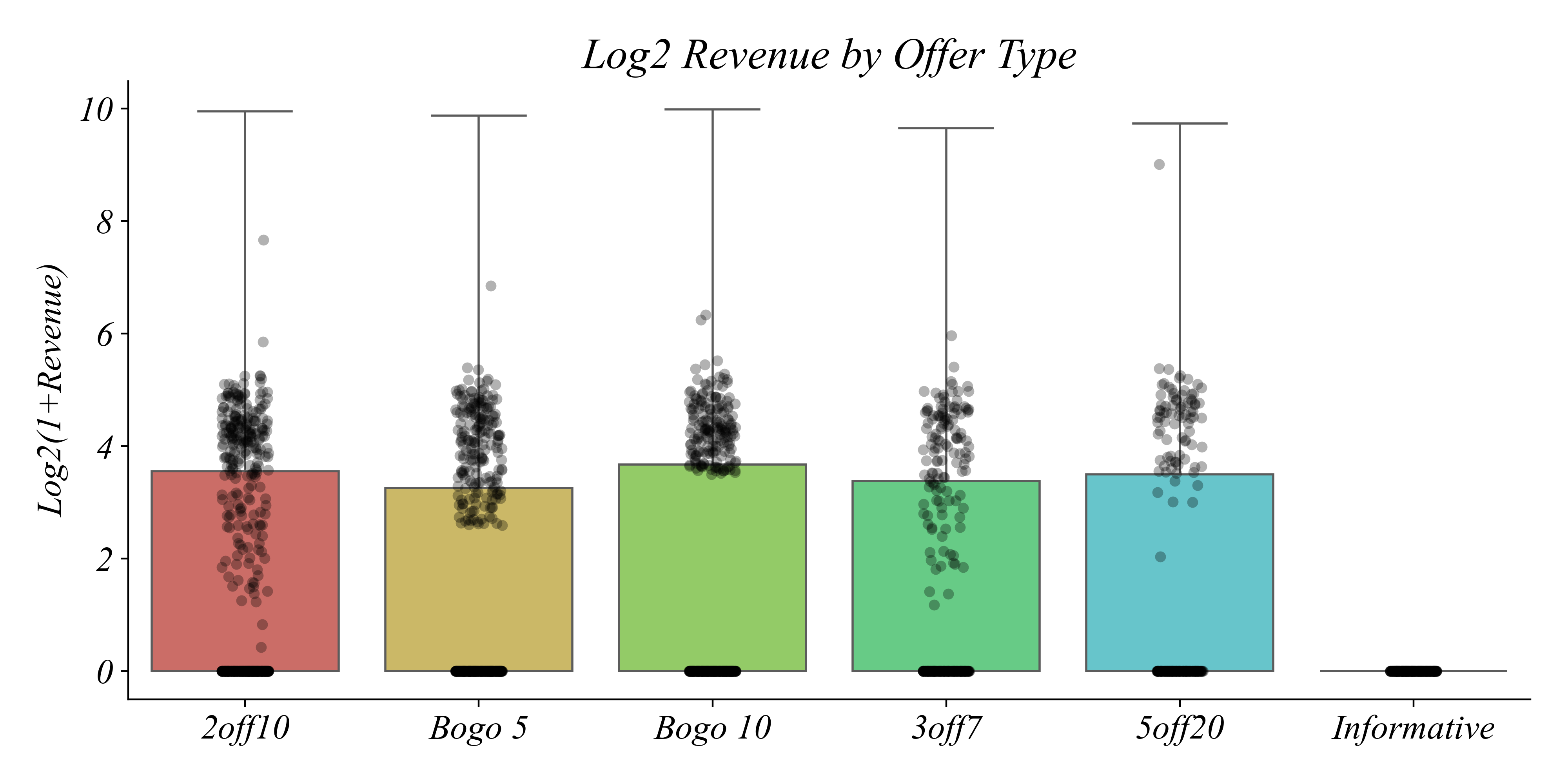
> why are there so many zeros?
Three Event Types
Not all rows are purchases
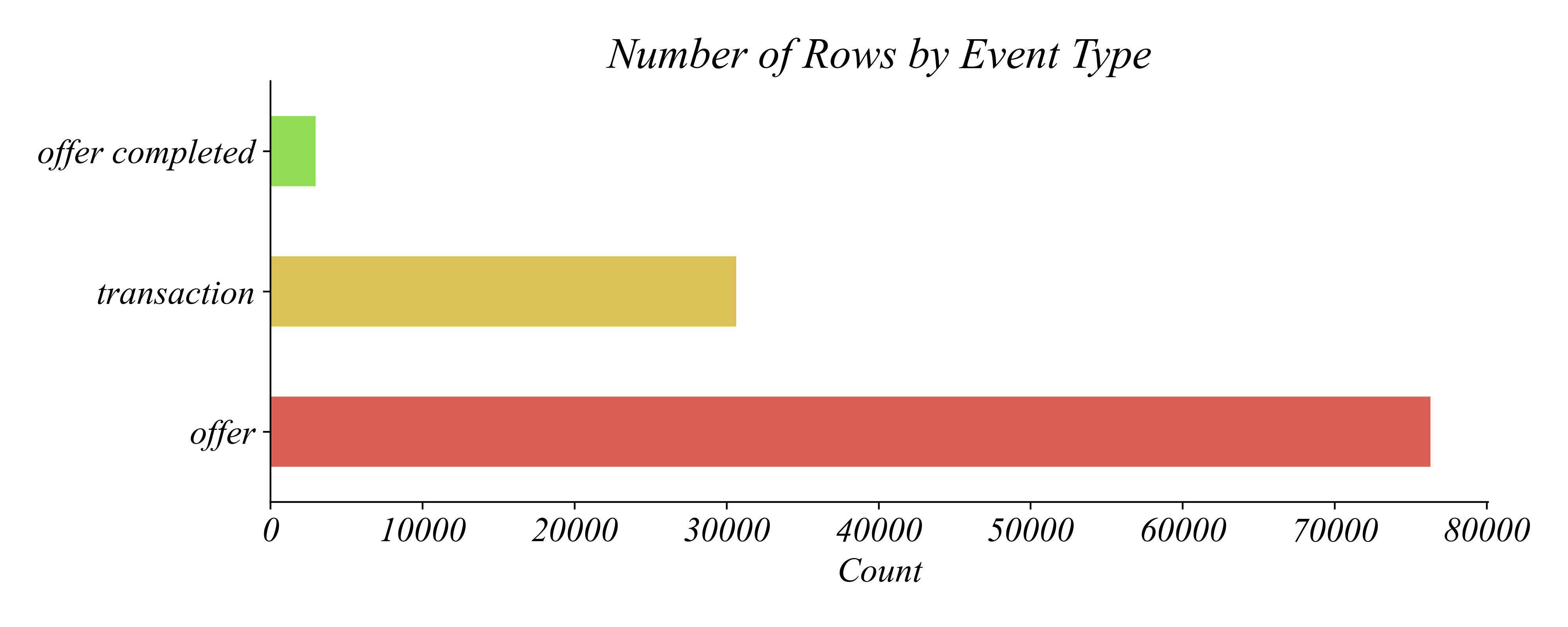
> most rows are offers, not transactions
Revenue by Event Type
Only transactions have revenue
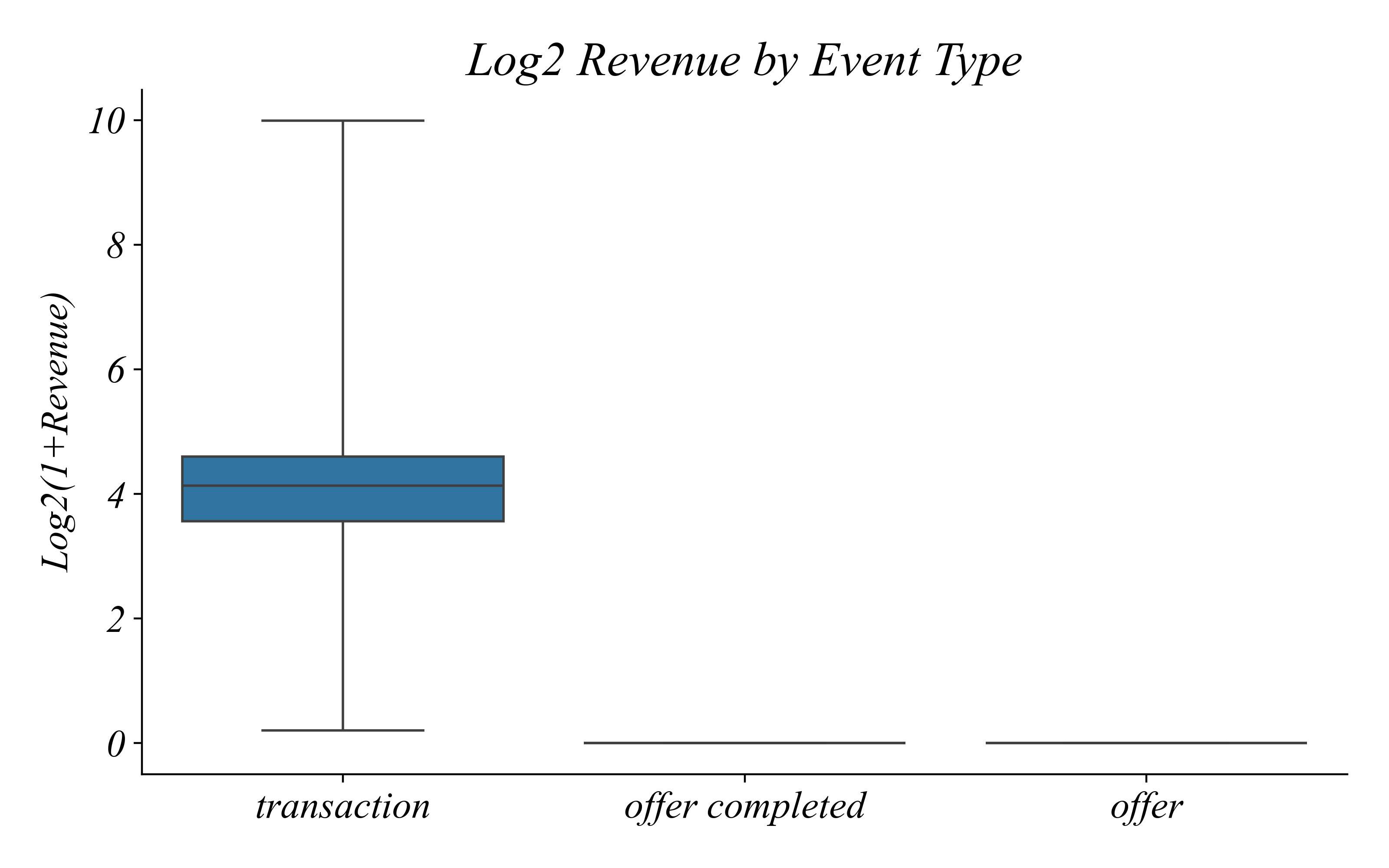
> offers and completions have zero revenue — that’s why we see so many zeros
Summarize Transactions
Every row is a real purchase.
> which offer type has higher spending?
Distributions by Offer Type
Each point is one transaction
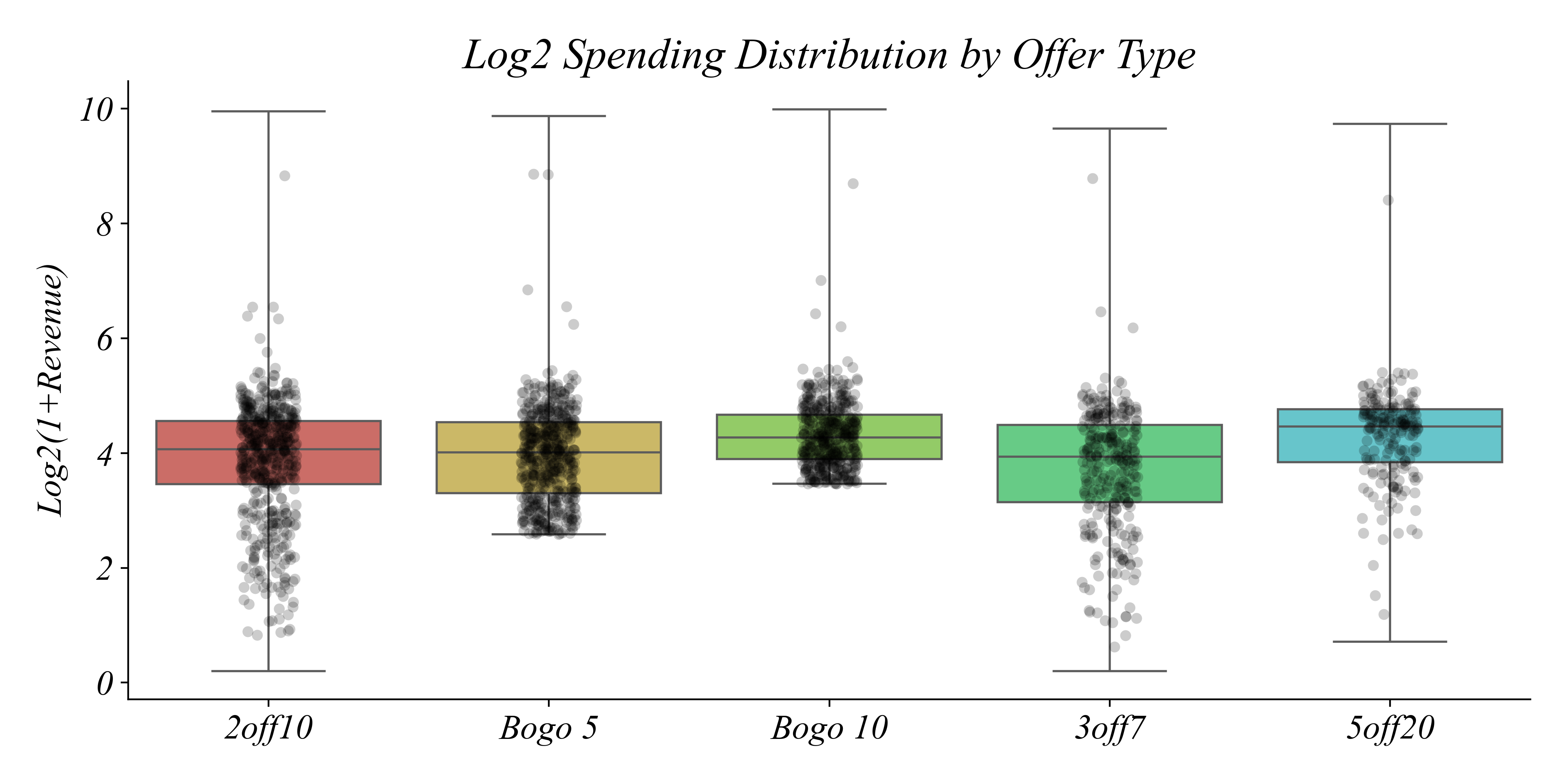
> substantial variation within each offer type
> why are there small purchases in 5off20?
Comparing Two Offers
BOGO 5 vs BOGO 10: Do buyers respond differently?
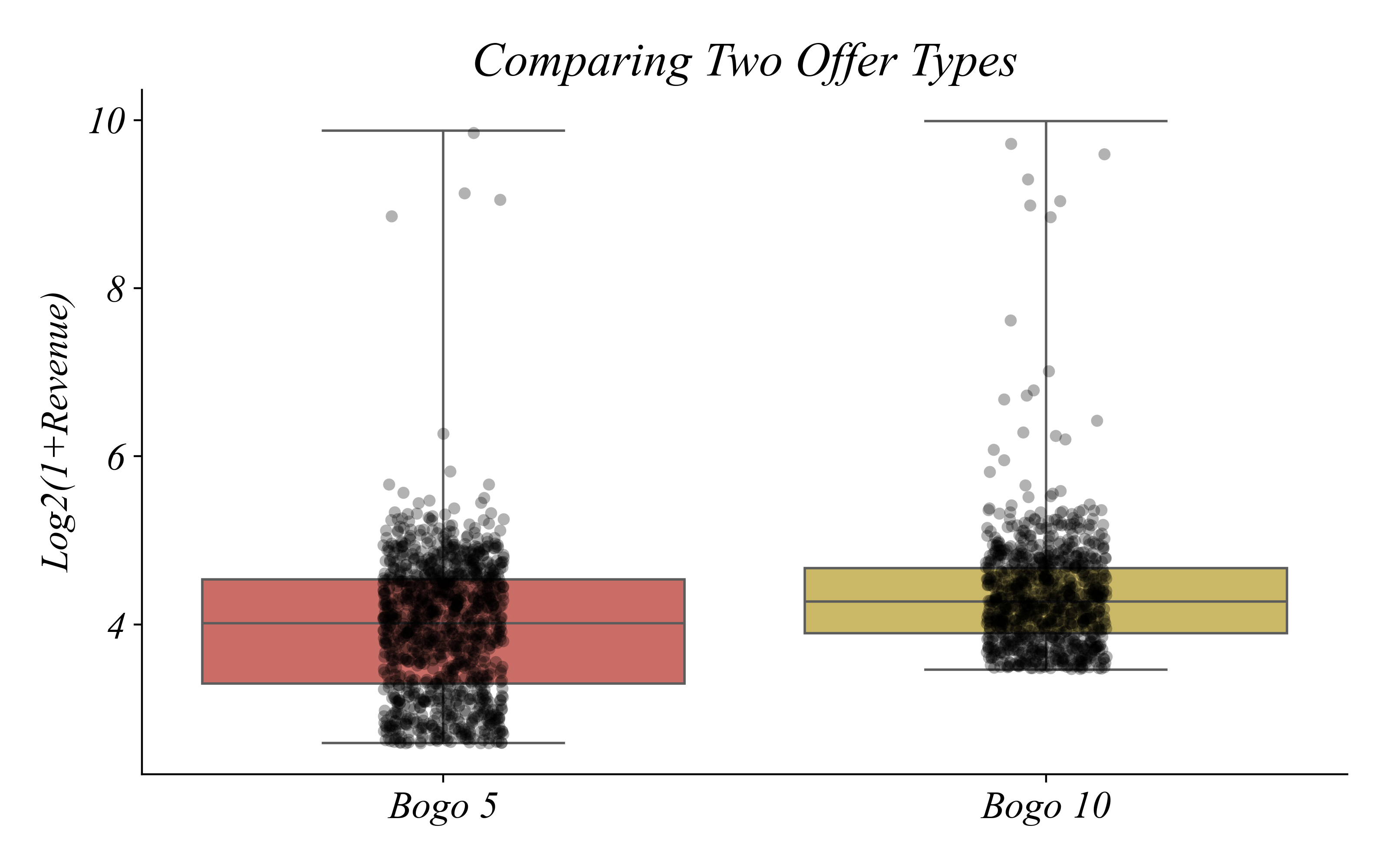
> BOGO 10 has higher average spending — but look at the overlap
The Overlap Problem
Many BOGO 5 buyers spent more than BOGO 10 buyers
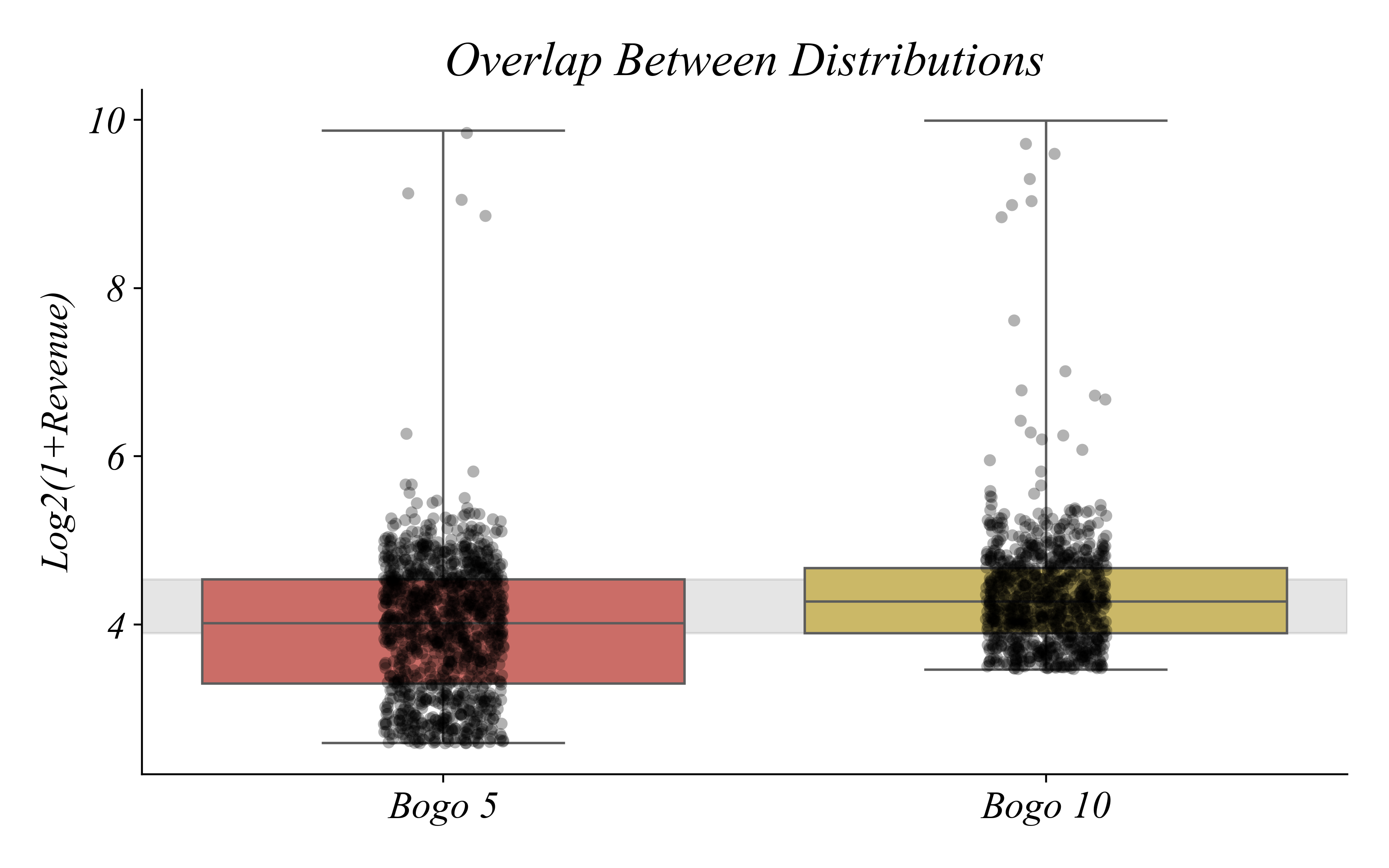
> when distributions overlap this much, is the difference meaningful?